cross-posted from: https://lemmy.world/post/3879861
> # Beating GPT-4 on HumanEval with a Fine-Tuned CodeLlama-34B
>
> Hello everyone! This post marks an exciting moment for [email protected] and everyone in the open-source large language model and AI community.
>
> We appear to have a new contender on the block, a model apparently capable of surpassing OpenAI's state of the art ChatGPT-4 in coding evals (evaluations).
>
> This is huge. Not too long ago I made an offhand comment on us catching up to GPT-4 within a year. I did not expect that prediction to end up being reality in half the time. Let's hope this isn't a one-off scenario and that we see a new wave of open-source models that begin to challenge OpenAI.
>
> Buckle up, it's going to get interesting!
>
> Here's some notes from the blog, which you should visit and read in its entirety:
>
> - https://www.phind.com/blog/code-llama-beats-gpt4
>
> ---
> # [Blog Post](https://www.phind.com/blog/code-llama-beats-gpt4)
>
> We have fine-tuned CodeLlama-34B and CodeLlama-34B-Python on an internal Phind dataset that achieved **67.6% and 69.5% pass@1 on HumanEval**, respectively. GPT-4 achieved 67% according to their official technical report in March. To ensure result validity, we applied OpenAI's decontamination methodology to our dataset.
>
> The CodeLlama models released yesterday demonstrate impressive performance on HumanEval.
>
> - CodeLlama-34B achieved 48.8% pass@1 on HumanEval
> - CodeLlama-34B-Python achieved 53.7% pass@1 on HumanEval
>
> We have fine-tuned both models on a proprietary dataset of ~80k high-quality programming problems and solutions. Instead of code completion examples, this dataset features instruction-answer pairs, setting it apart structurally from HumanEval. We trained the Phind models over two epochs, for a total of ~160k examples. LoRA was not used — both models underwent a native fine-tuning. We employed DeepSpeed ZeRO 3 and Flash Attention 2 to train these models in three hours using 32 A100-80GB GPUs, with a sequence length of 4096 tokens.
>
> Furthermore, we applied OpenAI's decontamination methodology to our dataset to ensure valid results, and **found no contaminated examples.**
>
> The methodology is:
>
> - For each evaluation example, we randomly sampled three substrings of 50 characters or used the entire example if it was fewer than 50 characters.
> - A match was identified if any sampled substring was a substring of the processed training example.
>
> For further insights on the decontamination methodology, please refer to Appendix C of OpenAI's technical report. Presented below are the pass@1 scores we achieved with our fine-tuned models:
>
> - Phind-CodeLlama-34B-v1 achieved **67.6% pass@1** on HumanEval
> - Phind-CodeLlama-34B-Python-v1 achieved **69.5% pass@1** on HumanEval
>
> ### Download
>
> We are releasing both models on Huggingface for verifiability and to bolster the open-source community. We welcome independent verification of results.
>
> - https://huggingface.co/Phind/Phind-CodeLlama-34B-v1
> - https://huggingface.co/Phind/Phind-CodeLlama-34B-Python-v1
>
> ---
>
> If you get a chance to try either of these models out, let us know how it goes in the comments below!
>
> If you found anything about this post interesting, consider subscribing to [email protected].
>
> Cheers to the power of open-source! May we continue the fight for optimization, efficiency, and performance.
cross-posted from: https://lemmy.world/post/3350022
> **Incognito Pilot: The Next-Gen AI Code Interpreter for Sensitive Data**
>
> Hello everyone! Today marks the first day of a new series of posts featuring projects in my [**GitHub Stars**](https://github.com/adynblaed?tab=stars).
>
> Most of these repos are FOSS & FOSAI focused, meaning they should be hackable, free, and (mostly) open-source.
>
> We're going to kick this series off by sharing [**Incognito Pilot**](https://github.com/silvanmelchior/IncognitoPilot). It’s like the ChatGPT Code Interpreter but for those who prioritize data privacy.
>
> 
>
> **Project Summary from ChatGPT-4**:
>
> **Features:**
>
> - Powered by Large Language Models like GPT-4 and Llama 2.
> - Run code and execute tasks with Python interpreter.
> - _Privacy_: Interacts with cloud but sensitive data stays local.
> - **Local or Remote**: Choose between local LLMs (like Llama 2) or API (like GPT-4) with data approval mechanism.
>
> You can use Incognito Pilot to:
>
> - Analyse data, create visualizations.
> - Convert files, e.g., video to gif.
> - Internet access for tasks like downloading data.
>
> Incognito Pilot ensures data privacy while leveraging GPT-4's capabilities.
>
> **Getting Started:**
>
> 1. **Installation**:
>
> - Use Docker (For Llama 2, check dedicated installation).
> - Create a folder for Incognito Pilot to access. Example: `/home/user/ipilot`.
> - Have an OpenAI account & API key.
> - Use the provided docker command to run.
> - Access via: [http://localhost:3030](http://localhost:3030/)
> - _Bonus_: Works with OpenAI's free trial credits (For GPT-3.5).
> 2. **First Steps**:
>
> - Chat with the interface: Start by saying "Hi".
> - Get familiar: Command it to print "Hello World".
> - Play around: Make it create a text file with numbers.
>
> **Notes**:
>
> - Data you enter and approved code results are sent to cloud APIs.
> - All data is processed locally.
> - Advanced users can customize Python interpreter packages for added functionalities.
>
> **FAQs**:
>
> - **Comparison with ChatGPT Code Interpreter**: Incognito Pilot offers a balance between privacy and functionality. It allows internet access, and can be run on powerful machines for larger tasks.
>
> - **Why use Incognito Pilot over just ChatGPT**: Multi-round code execution, tons of pre-installed dependencies, and a sandboxed environment.
>
> - **Data Privacy with Cloud APIs**: Your core data remains local. Only meta-data approved by you gets sent to the API, ensuring a controlled and conscious usage.
>
> ---
>
> Personally, my only concern using ChatGPT has always been about data privacy. This explores an interesting way to solve that while still getting the state of the art performance that OpenAI has managed to maintain (so far).
>
> I am all for these pro-privacy projects. I hope to see more emerge!
>
> If you get a chance to try this, let us know your experience in the comments below!
>
> ---
>
> **Links from this Post**
> - https://github.com/adynblaed?tab=stars
> - https://github.com/silvanmelchior/IncognitoPilot
>- Subscribe to [email protected]!
I used to feel the same way until I found some very interesting performance results from 3B and 7B parameter models.
Granted, it wasn’t anything I’d deploy to production - but using the smaller models to prototype quick ideas is great before having to rent a gpu and spend time working with the bigger models.
Give a few models a try! You might be pleasantly surprised. There’s plenty to choose from too. You will get wildly different results depending on your use case and prompting approach.
Let us know if you end up finding one you like! I think it is only a matter of time before we’re running 40B+ parameters at home (casually).
[Click Here to be Taken to the Megathread!](https://lemmy.world/post/2580983)
from [email protected]
> # **Vicuna v1.5 Has Been Released!**
>
> Shoutout to [[email protected]](https://lemmy.ml/GissaMittJobb) for catching this in an [earlier post](https://lemmy.world/post/2575250).
>
> Given Vicuna was a widely appreciated member of the original Llama series, it'll be exciting to see this model evolve and adapt with fresh datasets and new training and fine-tuning approaches.
>
> Feel free using this megathread to chat about Vicuna and any of your experiences with Vicuna v1.5!
>
> # **Starting off with Vicuna v1.5**
>
> TheBloke is already sharing models!
>
> ## **Vicuna v1.5 GPTQ**
>
> ### 7B
> - [Vicuna-7B-v1.5-GPTQ](https://huggingface.co/TheBloke/vicuna-7B-v1.5-GPTQ)
> - [Vicuna-7B-v1.5-16K-GPTQ](https://huggingface.co/TheBloke/vicuna-7B-v1.5-16K-GPTQ)
>
> ### 13B
> - [Vicuna-13B-v1.5-GPTQ](https://huggingface.co/TheBloke/vicuna-13B-v1.5-GPTQ)
>
> ---
>
> ## **Vicuna Model Card**
>
> ### **Model Details**
>
> Vicuna is a chat assistant fine-tuned from Llama 2 on user-shared conversations collected from ShareGPT.
>
> #### Developed by: LMSYS
>
> - **Model type**: An auto-regressive language model based on the transformer architecture
> - **License**: Llama 2 Community License Agreement
> - **Finetuned from model**: Llama 2
>
> #### Model Sources
>
> - **Repository**: [https://github.com/lm-sys/FastChat](https://github.com/lm-sys/FastChat)
> - **Blog**: [https://lmsys.org/blog/2023-03-30-vicuna/](https://lmsys.org/blog/2023-03-30-vicuna/)
> - **Paper**: [https://arxiv.org/abs/2306.05685](https://arxiv.org/abs/2306.05685)
> - **Demo**: [https://chat.lmsys.org/](https://chat.lmsys.org/)
>
> #### Uses
>
> The primary use of Vicuna is for research on large language models and chatbots. The target userbase includes researchers and hobbyists interested in natural language processing, machine learning, and artificial intelligence.
>
> #### How to Get Started with the Model
>
> - Command line interface: https://github.com/lm-sys/FastChat#vicuna-weights
> - APIs (OpenAI API, Huggingface API): https://github.com/lm-sys/FastChat/tree/main#api
>
> #### Training Details
>
> Vicuna v1.5 is fine-tuned from Llama 2 using supervised instruction. The model was trained on approximately 125K conversations from ShareGPT.com.
>
> For additional details, please refer to the "Training Details of Vicuna Models" section in the appendix of the linked paper.
>
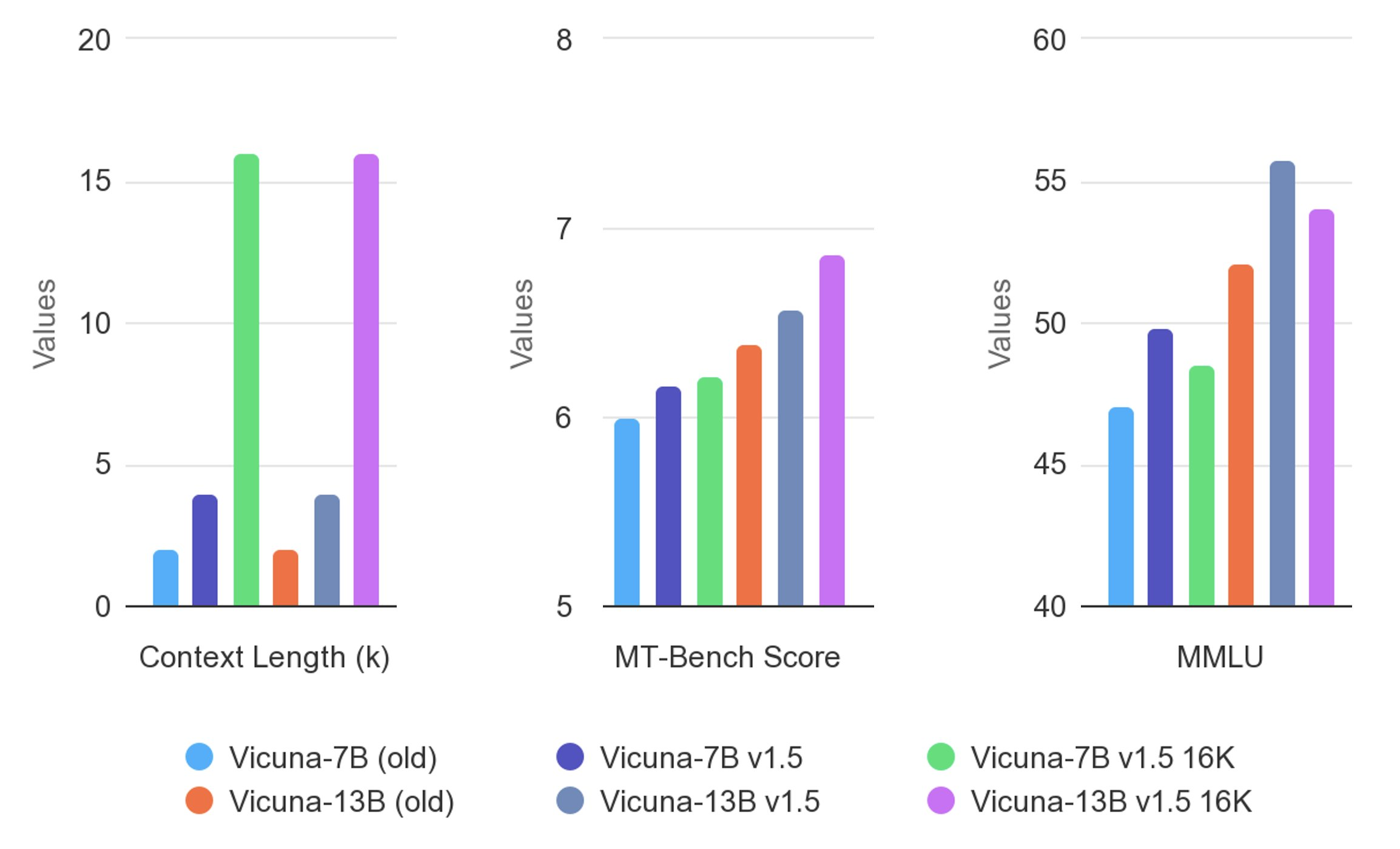
> #### Evaluation Results
>
> 
>
> Vicuna is evaluated using standard benchmarks, human preferences, and LLM-as-a-judge. For more detailed results, please refer to the paper and leaderboard.
cross-posted from: https://lemmy.world/post/2219010
> Hello everyone!
>
> We have officially hit 1,000 subscribers! How exciting!! Thank you for being a member of [email protected]. Whether you're a casual passerby, a hobby technologist, or an up-and-coming AI developer - I sincerely appreciate your interest and support in a future that is free and open for all.
>
> It can be hard to keep up with the rapid developments in AI, so I have decided to pin this at the top of our community to be a frequently updated LLM-specific resource hub and model index for all of your adventures in FOSAI.
>
> The ultimate goal of this guide is to become a gateway resource for anyone looking to get into free open-source AI (particularly text-based large language models). I will be doing a similar guide for image-based diffusion models soon!
>
> In the meantime, I hope you find what you're looking for! Let me know in the comments if there is something I missed so that I can add it to the guide for everyone else to see.
>
> ---
>
> ## **Getting Started With Free Open-Source AI**
>
> Have no idea where to begin with AI / LLMs? Try starting with our [Lemmy Crash Course for Free Open-Source AI](https://lemmy.world/post/76020).
>
> When you're ready to explore more resources see our [FOSAI Nexus](https://lemmy.world/post/814816) - a hub for all of the major FOSS & FOSAI on the cutting/bleeding edges of technology.
>
> If you're looking to jump right in, I recommend downloading [oobabooga's text-generation-webui](https://github.com/oobabooga/text-generation-webui) and installing one of the LLMs from [TheBloke](https://huggingface.co/TheBloke) below.
>
> Try both GGML and GPTQ variants to see which model type performs to your preference. See the hardware table to get a better idea on which parameter size you might be able to run (3B, 7B, 13B, 30B, 70B).
>
> ### **8-bit System Requirements**
>
> | Model | VRAM Used | Minimum Total VRAM | Card Examples | RAM/Swap to Load* |
> |-----------|-----------|--------------------|-------------------|-------------------|
> | LLaMA-7B | 9.2GB | 10GB | 3060 12GB, 3080 10GB | 24 GB |
> | LLaMA-13B | 16.3GB | 20GB | 3090, 3090 Ti, 4090 | 32 GB |
> | LLaMA-30B | 36GB | 40GB | A6000 48GB, A100 40GB | 64 GB |
> | LLaMA-65B | 74GB | 80GB | A100 80GB | 128 GB |
>
> ### **4-bit System Requirements**
>
> | Model | Minimum Total VRAM | Card Examples | RAM/Swap to Load* |
> |-----------|--------------------|--------------------------------|-------------------|
> | LLaMA-7B | 6GB | GTX 1660, 2060, AMD 5700 XT, RTX 3050, 3060 | 6 GB |
> | LLaMA-13B | 10GB | AMD 6900 XT, RTX 2060 12GB, 3060 12GB, 3080, A2000 | 12 GB |
> | LLaMA-30B | 20GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 | 32 GB |
> | LLaMA-65B | 40GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000 | 64 GB |
>
> *System RAM (not VRAM), is utilized to initially load a model. You can use swap space if you do not have enough RAM to support your LLM.
>
> When in doubt, try starting with 3B or 7B models and work your way up to 13B+.
>
> ### **FOSAI Resources**
>
> **Fediverse / FOSAI**
> - [The Internet is Healing](https://www.youtube.com/watch?v=TrNE2fSCeFo)
> - [FOSAI Welcome Message](https://lemmy.world/post/67758)
> - [FOSAI Crash Course](https://lemmy.world/post/76020)
> - [FOSAI Nexus Resource Hub](https://lemmy.world/post/814816)
>
> **LLM Leaderboards**
> - [HF Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
> - [LMSYS Chatbot Arena](https://chat.lmsys.org/?leaderboard)
>
> **LLM Search Tools**
> - [LLM Explorer](https://llm.extractum.io/)
> - [Open LLMs](https://github.com/eugeneyan/open-llms)
>
> ---
>
> ## **Large Language Model Hub**
>
> [Download Models](https://huggingface.co/TheBloke)
>
> ### [oobabooga](https://github.com/oobabooga/text-generation-webui)
> text-generation-webui - a big community favorite gradio web UI by oobabooga designed for running almost any free open-source and large language models downloaded off of [HuggingFace](https://huggingface.co/TheBloke) which can be (but not limited to) models like LLaMA, llama.cpp, GPT-J, Pythia, OPT, and many others. Its goal is to become the [AUTOMATIC1111/stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) of text generation. It is highly compatible with many formats.
>
> ### [Exllama](https://github.com/turboderp/exllama)
> A standalone Python/C++/CUDA implementation of Llama for use with 4-bit GPTQ weights, designed to be fast and memory-efficient on modern GPUs.
>
> ### [gpt4all](https://github.com/nomic-ai/gpt4all)
> Open-source assistant-style large language models that run locally on your CPU. GPT4All is an ecosystem to train and deploy powerful and customized large language models that run locally on consumer-grade processors.
>
> ### [TavernAI](https://github.com/TavernAI/TavernAI)
> The original branch of software SillyTavern was forked from. This chat interface offers very similar functionalities but has less cross-client compatibilities with other chat and API interfaces (compared to SillyTavern).
>
> ### [SillyTavern](https://github.com/SillyTavern/SillyTavern)
> Developer-friendly, Multi-API (KoboldAI/CPP, Horde, NovelAI, Ooba, OpenAI+proxies, Poe, WindowAI(Claude!)), Horde SD, System TTS, WorldInfo (lorebooks), customizable UI, auto-translate, and more prompt options than you'd ever want or need. Optional Extras server for more SD/TTS options + ChromaDB/Summarize. Based on a fork of TavernAI 1.2.8
>
> ### [Koboldcpp](https://github.com/LostRuins/koboldcpp)
> A self contained distributable from Concedo that exposes llama.cpp function bindings, allowing it to be used via a simulated Kobold API endpoint. What does it mean? You get llama.cpp with a fancy UI, persistent stories, editing tools, save formats, memory, world info, author's note, characters, scenarios and everything Kobold and Kobold Lite have to offer. In a tiny package around 20 MB in size, excluding model weights.
>
> ### [KoboldAI-Client](https://github.com/KoboldAI/KoboldAI-Client)
> This is a browser-based front-end for AI-assisted writing with multiple local & remote AI models. It offers the standard array of tools, including Memory, Author's Note, World Info, Save & Load, adjustable AI settings, formatting options, and the ability to import existing AI Dungeon adventures. You can also turn on Adventure mode and play the game like AI Dungeon Unleashed.
>
> ### [h2oGPT](https://github.com/h2oai/h2ogpt)
> h2oGPT is a large language model (LLM) fine-tuning framework and chatbot UI with document(s) question-answer capabilities. Documents help to ground LLMs against hallucinations by providing them context relevant to the instruction. h2oGPT is fully permissive Apache V2 open-source project for 100% private and secure use of LLMs and document embeddings for document question-answer.
>
> ---
>
> ## **Models**
>
> ### The Bloke
> The Bloke is a developer who frequently releases quantized (GPTQ) and optimized (GGML) open-source, user-friendly versions of AI Large Language Models (LLMs).
>
> These conversions of popular models can be configured and installed on personal (or professional) hardware, bringing bleeding-edge AI to the comfort of your home.
>
> Support [TheBloke](https://huggingface.co/TheBloke) here.
>
> - [https://ko-fi.com/TheBlokeAI](https://ko-fi.com/TheBlokeAI)
>
> ---
>
> #### 70B
> - [Llama-2-70B-chat-GPTQ](https://huggingface.co/TheBloke/Llama-2-70B-chat-GPTQ)
> - [Llama-2-70B-Chat-GGML](https://huggingface.co/TheBloke/Llama-2-70B-Chat-GGML)
>
> - [Llama-2-70B-GPTQ](https://huggingface.co/TheBloke/Llama-2-70B-GPTQ)
> - [Llama-2-70B-GGML](https://huggingface.co/TheBloke/Llama-2-70B-GGML)
>
> - [llama-2-70b-Guanaco-QLoRA-GPTQ](https://huggingface.co/TheBloke/llama-2-70b-Guanaco-QLoRA-GPTQ)
>
> ---
>
> #### 30B
> - [30B-Epsilon-GPTQ](https://huggingface.co/TheBloke/30B-Epsilon-GPTQ)
>
> ---
>
> #### 13B
> - [Llama-2-13B-chat-GPTQ](https://huggingface.co/TheBloke/Llama-2-13B-chat-GPTQ)
> - [Llama-2-13B-chat-GGML](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML)
>
> - [Llama-2-13B-GPTQ](https://huggingface.co/TheBloke/Llama-2-13B-GPTQ)
> - [Llama-2-13B-GGML](https://huggingface.co/TheBloke/Llama-2-13B-GGML)
>
> - [llama-2-13B-German-Assistant-v2-GPTQ](https://huggingface.co/TheBloke/llama-2-13B-German-Assistant-v2-GPTQ)
> - [llama-2-13B-German-Assistant-v2-GGML](https://huggingface.co/TheBloke/llama-2-13B-German-Assistant-v2-GGML)
>
> - [13B-Ouroboros-GGML](https://huggingface.co/TheBloke/13B-Ouroboros-GGML)
> - [13B-Ouroboros-GPTQ](https://huggingface.co/TheBloke/13B-Ouroboros-GPTQ)
>
> - [13B-BlueMethod-GGML](https://huggingface.co/TheBloke/13B-BlueMethod-GGML)
> - [13B-BlueMethod-GPTQ](https://huggingface.co/TheBloke/13B-BlueMethod-GPTQ)
>
> - [llama-2-13B-Guanaco-QLoRA-GGML](https://huggingface.co/TheBloke/llama-2-13B-Guanaco-QLoRA-GGML)
> - [llama-2-13B-Guanaco-QLoRA-GPTQ](https://huggingface.co/TheBloke/llama-2-13B-Guanaco-QLoRA-GPTQ)
>
> - [Dolphin-Llama-13B-GGML](https://huggingface.co/TheBloke/Dolphin-Llama-13B-GGML)
> - [Dolphin-Llama-13B-GPTQ](https://huggingface.co/TheBloke/Dolphin-Llama-13B-GPTQ)
>
> - [MythoLogic-13B-GGML](https://huggingface.co/TheBloke/MythoLogic-13B-GGML)
> - [MythoBoros-13B-GPTQ](https://huggingface.co/TheBloke/MythoBoros-13B-GPTQ)
>
> - [WizardLM-13B-V1.2-GPTQ](https://huggingface.co/TheBloke/WizardLM-13B-V1.2-GPTQ)
> - [WizardLM-13B-V1.2-GGML](https://huggingface.co/TheBloke/WizardLM-13B-V1.2-GGML)
>
> - [OpenAssistant-Llama2-13B-Orca-8K-3319-GGML](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-GGML)
>
> ---
>
> #### 7B
> - [Llama-2-7B-GPTQ](https://huggingface.co/TheBloke/Llama-2-7B-GPTQ)
> - [Llama-2-7B-GGML](https://huggingface.co/TheBloke/Llama-2-7B-GGML)
>
> - [Llama-2-7b-Chat-GPTQ](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GPTQ)
> - [LLongMA-2-7B-GPTQ](https://huggingface.co/TheBloke/LLongMA-2-7B-GPTQ)
>
> - [llama-2-7B-Guanaco-QLoRA-GPTQ](https://huggingface.co/TheBloke/llama-2-7B-Guanaco-QLoRA-GPTQ)
> - [llama-2-7B-Guanaco-QLoRA-GGML](https://huggingface.co/TheBloke/llama-2-7B-Guanaco-QLoRA-GGML)
>
> - [llama2_7b_chat_uncensored-GPTQ](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GPTQ)
> - [llama2_7b_chat_uncensored-GGML](https://huggingface.co/TheBloke/llama2_7b_chat_uncensored-GGML)
>
> ---
>
> ## **More Models**
> - [Any of KoboldAI's Models](https://huggingface.co/KoboldAI)
>
> - [Luna-AI-Llama2-Uncensored-GPTQ](https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GPTQ)
>
> - [Nous-Hermes-Llama2-GGML](https://huggingface.co/TheBloke/Nous-Hermes-Llama2-GGML)
> - [Nous-Hermes-Llama2-GPTQ](https://huggingface.co/TheBloke/Nous-Hermes-Llama2-GPTQ)
>
> - [FreeWilly2-GPTQ](https://huggingface.co/TheBloke/FreeWilly2-GPTQ)
>
> ---
>
> ## **GL, HF!**
>
> Are you an LLM Developer? Looking for a shoutout or project showcase? Send me a message and I'd be more than happy to share your work and support links with the community.
>
> If you haven't already, consider subscribing to the free open-source AI community at [email protected] where I will do my best to make sure you have access to free open-source artificial intelligence on the bleeding edge.
>
> Thank you for reading!
cross-posted from: https://lemmy.world/post/1894070
> ## **Welcome to the Llama-2 FOSAI & LLM Roundup Series!**
>
> **(Summer 2023 Edition)**
>
> Hello everyone!
>
> The wave of innovation I mentioned in our [Llama-2 announcement](https://lemmy.world/post/1750098) is already on its way. The first tsunami of base models and configurations are being released as you read this post.
>
> That being said, I'd like to take a moment to shoutout [TheBloke](https://huggingface.co/TheBloke), who is rapidly converting many of these models for the greater good of FOSS & FOSAI.
>
> You can support [TheBloke](https://huggingface.co/TheBloke) here.
> - https://ko-fi.com/TheBlokeAI
>
> Below you will find all of the latest Llama-2 models that are FOSAI friendly. This means they are commercially available, ready to use, and open for development. I will be continuing this series exclusively for Llama models. I have a feeling it will continue being a popular choice for quite some time. I will consider giving other foundational models a similar series if they garner enough support and consideration. For now, enjoy this new herd of Llamas!
>
> All that you need to get started is capable hardware and a few moments setting up your inference platform (selected from any of your preferred software choices in the [Lemmy Crash Course for Free Open-Source AI](https://lemmy.world/post/76020)
> or [FOSAI Nexus](https://lemmy.world/post/814816) resource, which is also shared at the bottom of this post).
>
> Keep reading to learn more about the exciting new models coming out of Llama-2!
>
> ### **8-bit System Requirements**
>
> | Model | VRAM Used | Minimum Total VRAM | Card Examples | RAM/Swap to Load* |
> |-----------|-----------|--------------------|-------------------|-------------------|
> | LLaMA-7B | 9.2GB | 10GB | 3060 12GB, 3080 10GB | 24 GB |
> | LLaMA-13B | 16.3GB | 20GB | 3090, 3090 Ti, 4090 | 32 GB |
> | LLaMA-30B | 36GB | 40GB | A6000 48GB, A100 40GB | 64 GB |
> | LLaMA-65B | 74GB | 80GB | A100 80GB | 128 GB |
>
> ### **4-bit System Requirements**
>
> | Model | Minimum Total VRAM | Card Examples | RAM/Swap to Load* |
> |-----------|--------------------|--------------------------------|-------------------|
> | LLaMA-7B | 6GB | GTX 1660, 2060, AMD 5700 XT, RTX 3050, 3060 | 6 GB |
> | LLaMA-13B | 10GB | AMD 6900 XT, RTX 2060 12GB, 3060 12GB, 3080, A2000 | 12 GB |
> | LLaMA-30B | 20GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 | 32 GB |
> | LLaMA-65B | 40GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000 | 64 GB |
>
> *System RAM (not VRAM), is utilized to initially load a model. You can use swap space if you do not have enough RAM to support your LLM.
>
> ---
>
> ### **The Bloke**
> One of the most popular and consistent developers releasing consumer-friendly versions of LLMs. These active conversions of trending models allow for many of us to run these GPTQ or GGML variants at home on our own PCs and hardware.
>
> **70B**
>
> - [TheBloke/Llama-2-70B-chat-GPTQ](https://huggingface.co/TheBloke/Llama-2-70B-chat-GPTQ)
>
> - [TheBloke/Llama-2-70B-Chat-fp16](https://huggingface.co/TheBloke/Llama-2-70B-Chat-fp16)
>
> - [TheBloke/Llama-2-70B-GPTQ](https://huggingface.co/TheBloke/Llama-2-70B-GPTQ)
>
> - [TheBloke/Llama-2-70B-fp16](https://huggingface.co/TheBloke/Llama-2-70B-fp16)
>
> **13B**
>
> - [TheBloke/Llama-2-13B-chat-GPTQ](https://huggingface.co/TheBloke/Llama-2-13B-chat-GPTQ)
>
> - [TheBloke/Llama-2-13B-chat-GGML](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML)
>
> - [TheBloke/Llama-2-13B-GPTQ](https://huggingface.co/TheBloke/Llama-2-13B-GPTQ)
>
> - [TheBloke/Llama-2-13B-GGML](https://huggingface.co/TheBloke/Llama-2-13B-GGML)
>
> - [TheBloke/Llama-2-13B-fp16](https://huggingface.co/TheBloke/Llama-2-13B-fp16)
>
> **7B**
>
> - [TheBloke/Llama-2-7B-GPTQ](https://huggingface.co/TheBloke/Llama-2-7B-GPTQ)
>
> - [TheBloke/Llama-2-7B-GGML)](https://huggingface.co/TheBloke/Llama-2-7B-GGML)
>
> - [TheBloke/Llama-2-7B-fp16](https://huggingface.co/TheBloke/Llama-2-7B-fp16)
>
> - [TheBloke/Llama-2-7B-fp16](https://huggingface.co/TheBloke/Llama-2-7B-fp16)
>
> - [TheBloke/Llama-2-7b-Chat-GPTQ](https://huggingface.co/TheBloke/Llama-2-7b-Chat-GPTQ)
>
> ### **LLongMA**
> LLongMA-2, a suite of Llama-2 models, trained at 8k context length using linear positional interpolation scaling.
>
> **13B**
>
> - [conceptofmind/LLongMA-2-13b](https://huggingface.co/conceptofmind/LLongMA-2-13b)
>
> **7B**
>
> - [conceptofmind/LLongMA-2-7b](https://huggingface.co/conceptofmind/LLongMA-2-7b)
>
> Also available from The Bloke in GPTQ and GGML formats:
>
> **7B**
>
> - [TheBloke/LLongMA-2-7B-GPTQ](https://huggingface.co/TheBloke/LLongMA-2-7B-GPTQ)
>
> - [TheBloke/LLongMA-2-7B-GGML](https://huggingface.co/TheBloke/LLongMA-2-7B-GGML)
>
> ### **Puffin**
> The first commercially available language model released by Nous Research! Available in 13B parameters.
>
> **13B**
>
> - [NousResearch/Redmond-Puffin-13B-GGML](https://huggingface.co/NousResearch/Redmond-Puffin-13B-GGML)
>
> - [NousResearch/Redmond-Puffin-13B](https://huggingface.co/NousResearch/Redmond-Puffin-13B)
>
> Also available from The Bloke in GPTQ and GGML formats:
>
> **13B**
>
> - [TheBloke/Redmond-Puffin-13B-GPTQ](https://huggingface.co/TheBloke/Redmond-Puffin-13B-GPTQ)
>
> - [TheBloke/Redmond-Puffin-13B-GGML](https://huggingface.co/TheBloke/Redmond-Puffin-13B-GGML)
>
> ### **Other Models**
> Leaving a section here for 'other' LLMs or fine tunings derivative of Llama-2 models.
>
> **7B**
>
> - [georgesung/llama2_7b_chat_uncensored](https://huggingface.co/georgesung/llama2_7b_chat_uncensored)
>
> ---
>
> ### **Getting Started w/ FOSAI!**
>
> Have no idea where to begin with AI/LLMs? [Try starting here with ](https://understandgpt.ai/docs/getting-started/what-is-a-llm) [UnderstandGPT](https://understandgpt.ai/) to learn the basics of LLMs before visiting our [Lemmy Crash Course for Free Open-Source AI](https://lemmy.world/post/76020)
>
> If you're looking to explore more resources, see our [FOSAI Nexus](https://lemmy.world/post/814816) for a list of all the major FOSS/FOSAI in the space.
>
> If you're looking to jump right in, visit some of the links below and stick to models that are <13B in parameter (unless you have the power and hardware to spare).
>
> **FOSAI Resources**
>
> **Fediverse / FOSAI**
> - [The Internet is Healing](https://www.youtube.com/watch?v=TrNE2fSCeFo)
> - [FOSAI Welcome Message](https://lemmy.world/post/67758)
> - [FOSAI Crash Course](https://lemmy.world/post/76020)
> - [FOSAI Nexus Resource Hub](https://lemmy.world/post/814816)
>
> **LLM Leaderboards**
> - [HF Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
> - [LMSYS Chatbot Arena](https://chat.lmsys.org/?leaderboard)
>
> **LLM Search Tools**
> - [LLM Explorer](https://llm.extractum.io/)
> - [Open LLMs](https://github.com/eugeneyan/open-llms)
>
> ### **GL, HF!**
>
> If you found anything about this post interesting - consider subscribing to [email protected] where I do my best to keep you in the know about the most important updates in free open-source artificial intelligence.
>
> I will try to continue doing this series season by season, making this a living post for the rest of this summer. If I have missed a noteworthy model, don't hesitate to let me know in the comments so I can keep this resource up-to-date.
>
> Thank you for reading! I hope you find what you're looking for. Be sure to subscribe and bookmark the [main post](https://lemmy.world/post/1894070) if you want a quick one-stop shop for all of the new Llama-2 models that will be emerging the rest of this summer!
cross-posted from: https://lemmy.world/post/1750098
## **[Introducing Llama 2 - Meta's Next Generation Free Open-Source Artificially Intelligent Large Language Model](https://ai.meta.com/llama/)**
It's incredible it's already here! This is great news for everyone in free open-source artificial intelligence.
Llama 2 unleashes Meta's (previously) closed model (Llama) to become free open-source AI, accelerating access and development for large language models (LLMs).
This marks a significant step in machine learning and deep learning technologies. With this move, a widely supported LLM can become a viable choice for businesses, developers, and entrepreneurs to innovate our future using a model that the community has been eagerly awaiting since its [initial leak earlier this year](https://www.theverge.com/2023/3/8/23629362/meta-ai-language-model-llama-leak-online-misuse).
- [Meta Announcement](https://ai.meta.com/llama/)
- [Meta Overview](https://ai.meta.com/resources/models-and-libraries/llama/)
- [Github](https://github.com/facebookresearch/llama/tree/main)
- [Paper](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/)
**Here are some highlights from the [official Meta AI announcement](https://ai.meta.com/llama/):**
## **Llama 2**
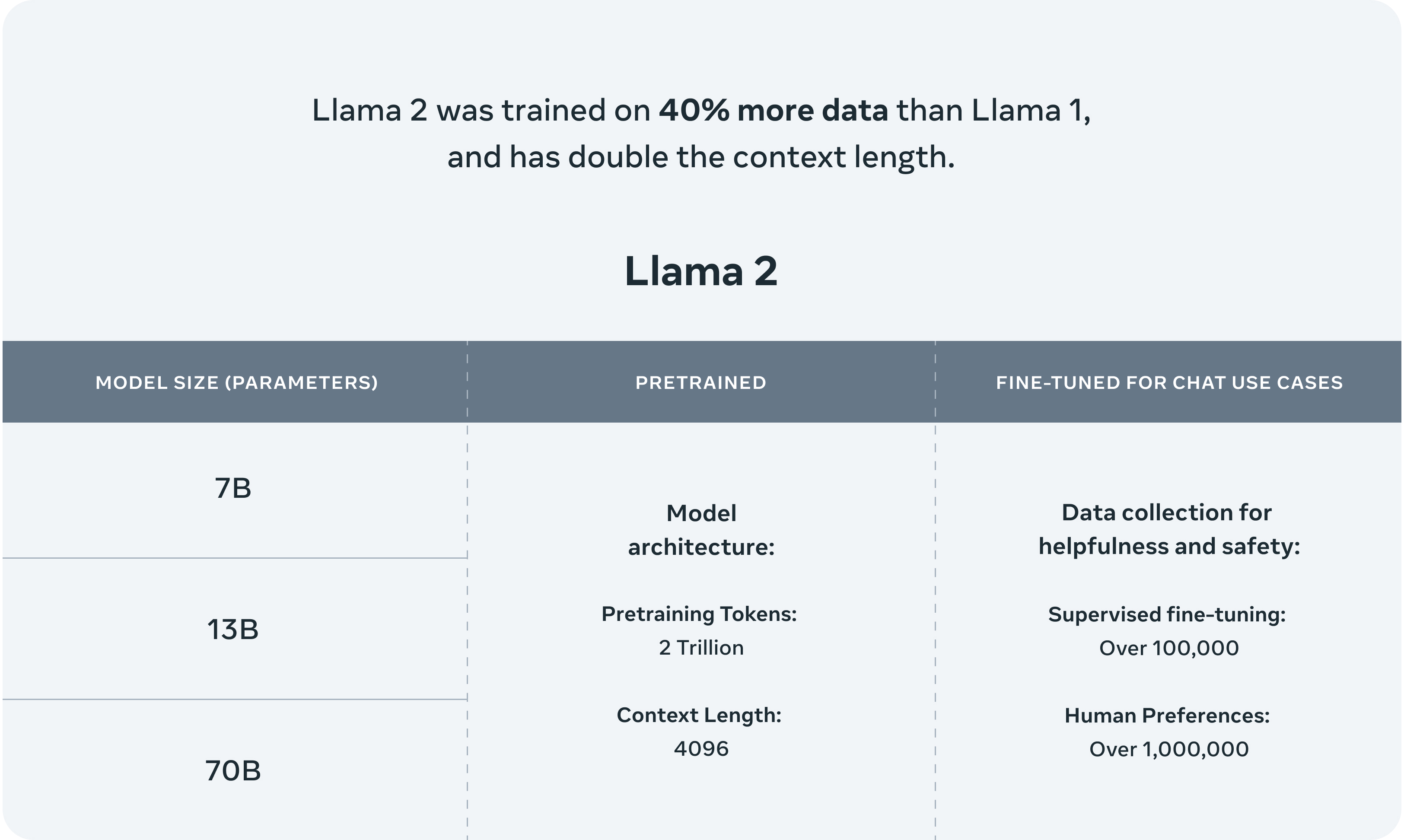
>In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases.
>
>Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closedsource models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
>Llama 2 pretrained models are trained on 2 trillion tokens, and have double the context length than Llama 1. Its fine-tuned models have been trained on over 1 million human annotations.
## **Inside the Model**
- [Technical details](https://ai.meta.com/resources/models-and-libraries/llama/)
### With each model download you'll receive:
- Model code
- Model Weights
- README (User Guide)
- Responsible Use Guide
- License
- Acceptable Use Policy
- Model Card
## **Benchmarks**
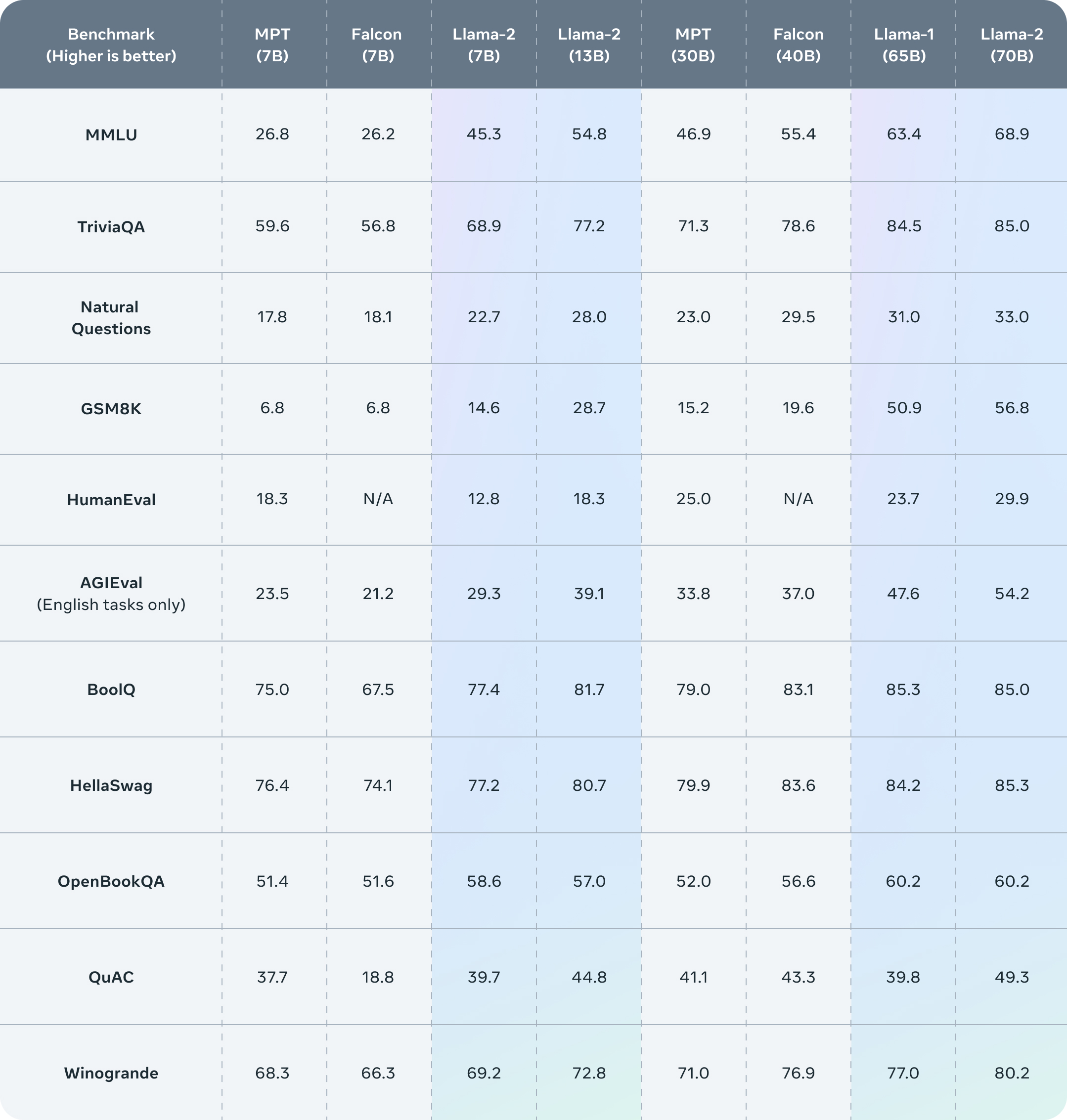
>Llama 2 outperforms other open source language models on many external benchmarks, including reasoning, coding, proficiency, and knowledge tests. It was pretrained on publicly available online data sources. The fine-tuned model, Llama-2-chat, leverages publicly available instruction datasets and over 1 million human annotations.
## **RLHF & Training**
>Llama-2-chat uses reinforcement learning from human feedback to ensure safety and helpfulness. Training Llama-2-chat: Llama 2 is pretrained using publicly available online data. An initial version of Llama-2-chat is then created through the use of supervised fine-tuning. Next, Llama-2-chat is iteratively refined using Reinforcement Learning from Human Feedback (RLHF), which includes rejection sampling and proximal policy optimization (PPO).

## **The License**
>Our model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. Our mission is to empower individuals, and industry through this opportunity, while fostering an environment of discovery and ethical AI advancements.
>**Partnerships**
>We have a broad range of supporters around the world who believe in our open approach to today’s AI — companies that have given early feedback and are excited to build with Llama 2, cloud providers that will include the model as part of their offering to customers, researchers committed to doing research with the model, and people across tech, academia, and policy who see the benefits of Llama and an open platform as we do.
## **The/CUT**
With the release of Llama 2, Meta has opened up new possibilities for the development and application of large language models. This free open-source AI not only accelerates access but also allows for greater innovation in the field.
**Take Three**:
- **Video Game Analogy**: Just like getting a powerful, rare (or previously banned) item drop in a game, Llama 2's release gives developers a powerful tool they can use and customize for their unique quests in the world of AI.
- **Cooking Analogy**: Imagine if a world-class chef decided to share their secret recipe with everyone. That's Llama 2, a secret recipe now open for all to use, adapt, and improve upon in the kitchen of AI development.
- **Construction Analogy**: Llama 2 is like a top-grade construction tool now available to all builders. It opens up new possibilities for constructing advanced AI structures that were previously hard to achieve.
## **Links**
Here are the key resources discussed in this post:
- [Meta Announcement](https://ai.meta.com/llama/)
- [Meta Overview](https://ai.meta.com/resources/models-and-libraries/llama/)
- [Github](https://github.com/facebookresearch/llama/tree/main)
- [Paper](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/)
- [Technical details](https://ai.meta.com/resources/models-and-libraries/llama/)
Want to get started with free open-source artificial intelligence, but don't know where to begin?
Try starting here:
- [FOSAI Welcome Message](https://lemmy.world/post/67758)
- [FOSAI Crash Course](https://lemmy.world/post/76020)
- [FOSAI Nexus Resource Hub](https://lemmy.world/post/814816)
If you found anything else about this post interesting - consider subscribing to [email protected] where I do my best to keep you in the know about the most important updates in free open-source artificial intelligence.
This particular announcement is exciting to me because it may popularize open-source principles and practices for other enterprises and corporations to follow.
We should see some interesting models emerge out of Llama 2. I for one am looking forward to seeing where this will take us next. Get ready for another wave of innovation! This one is going to be big.
cross-posted from: https://lemmy.world/post/1709025
> # [FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/abs/2205.14135)
>
> [FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning](https://crfm.stanford.edu/2023/07/17/flash2.html)
>
> 
>
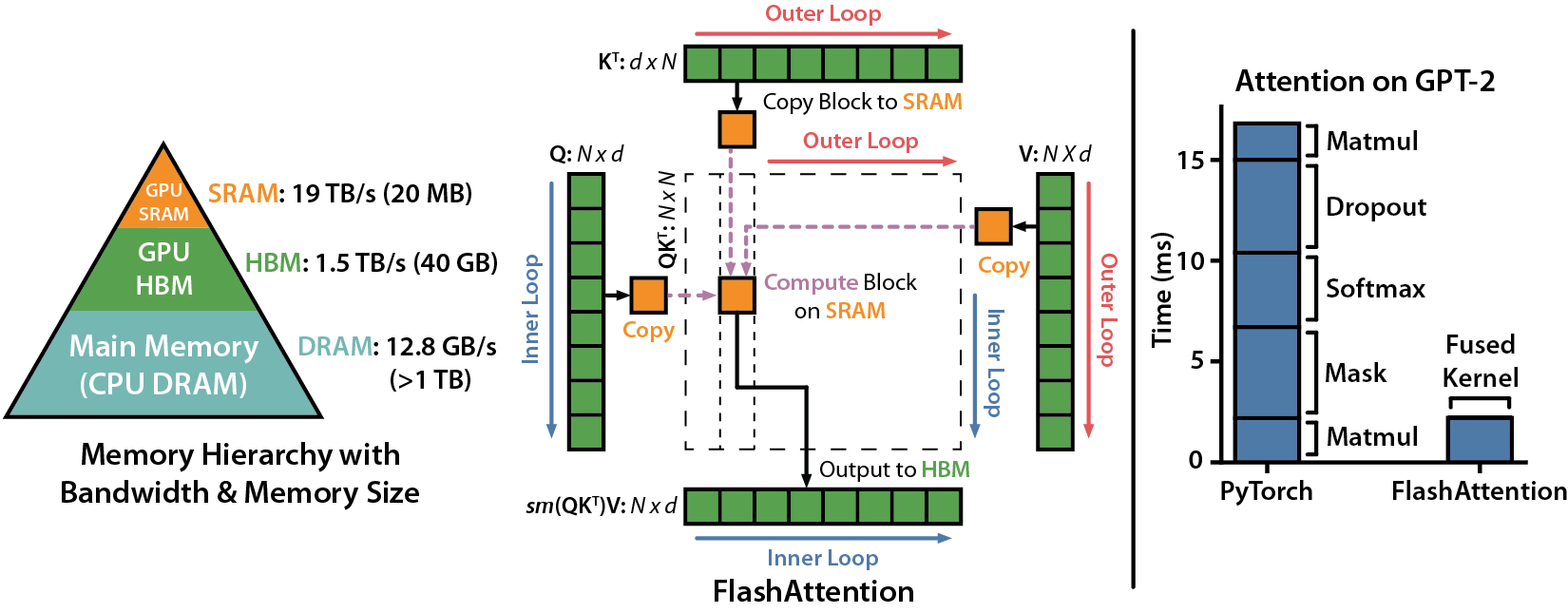
> Today, we explore an exciting new development: FlashAttention-2, a breakthrough in Transformer model scaling and performance. The attention layer, a key part of Transformer model architecture, has been a bottleneck in scaling to longer sequences due to its runtime and memory requirements. FlashAttention-2 tackles this issue by improving work partitioning and parallelism, leading to significant speedups and improved efficiency for many AI/LLMs.
>
> The significance of this development is huge. Transformers are fundamental to many current machine learning models, used in a wide array of applications from language modeling to image understanding and audio, video, and code generation. By making attention algorithms IO-aware and improving work partitioning, FlashAttention-2 gets closer to the efficiency of General Matrix to Matrix Multiplication (GEMM) operations, which are highly optimized for modern GPUs. This enables the training of larger and more complex models, pushing the boundaries of what's possible with machine learning both at home and in the lab.
>
> ## Features & Advancements
>
> FlashAttention-2 improves upon its predecessor by tweaking the algorithm to reduce the number of non-matrix multiplication FLOPs, parallelizing the attention computation, and distributing work within each thread block. These improvements lead to approximately 2x speedup compared to FlashAttention, reaching up to 73% of the theoretical maximum FLOPs/s.
>
> Relevant resources:
> - [Github](https://github.com/Dao-AILab/flash-attention)
> - [Blog post](https://crfm.stanford.edu/2023/07/17/flash2.html)
>
> ## Installation & Requirements
>
> To install FlashAttention-2, you'll need CUDA 11.4 and PyTorch 1.12 or above. The installation process is straightforward and can be done through pip or by compiling from source. Detailed instructions are provided on the Github page.
>
> Relevant resources:
> - [Github](https://github.com/Dao-AILab/flash-attention)
> - [Blog post](https://crfm.stanford.edu/2023/07/17/flash2.html)
>
> ## Supported Hardware & Datatypes
>
> FlashAttention-2 currently supports Ampere, Ada, or Hopper GPUs (e.g., A100, RTX 3090, RTX 4090, H100). Support for Turing GPUs (T4, RTX 2080) is coming soon. It supports datatype fp16 and bf16 (bf16 requires Ampere, Ada, or Hopper GPUs). All head dimensions up to 256 are supported.
>
> Relevant resources:
> - [Github](https://github.com/Dao-AILab/flash-attention)
> - [Blog post](https://crfm.stanford.edu/2023/07/17/flash2.html)
>
> ## The/CUT
>
> FlashAttention-2 is a significant leap forward in Transformer model scaling. By improving the efficiency of the attention layer, it allows for faster and more efficient training of larger models. This opens up new possibilities in machine learning applications, especially in systems or projects that need all the performance they can get.
>
> **Take Three**:
> Three big takeaways from this post:
>
> - **Performance Boost**: FlashAttention-2 is a significant improvement in Transformer architecture and provides a massive performance boost to AI/LLM models who utilize it. It manages to achieve a 2x speedup compared to its predecessor, FlashAttention. This allows for faster training of larger and more complex models, which can lead to breakthroughs in various machine learning applications at home (and in the lab).
>
> - **Efficiency and Scalability**: FlashAttention-2 improves the efficiency of attention computation in Transformers by optimizing work partitioning and parallelism. This allows the model to scale to longer sequence lengths, increasing its applicability in tasks that require understanding of larger context, such as language modeling, high-resolution image understanding, and code, audio, and video generation.
>
> - **Better Utilization of Hardware Resources**: FlashAttention-2 is designed to be IO-aware, taking into account the reads and writes between different levels of GPU memory. This leads to better utilization of hardware resources, getting closer to the efficiency of optimized matrix-multiply (GEMM) operations. It currently supports Ampere, Ada, or Hopper GPUs and is planning to extend support for Turing GPUs soon. This ensures that a wider range of machine learning practitioners and researchers can take advantage of this breakthrough.
>
> ## Links
> - [FlashAttention Paper](https://arxiv.org/abs/2205.14135)
> - [FlashAttention Post](https://crfm.stanford.edu/2023/07/17/flash2.html)
> - [Github Repository](https://github.com/Dao-AILab/flash-attention)
If you found anything about this post interesting - consider subscribing to [email protected] where I do my best to keep you informed in free open-source artificial intelligence.
Thank you for reading!
cross-posted from: https://lemmy.world/post/1535820
> > **[I'd like to share with you Petals: decentralized inference and finetuning of large language models](https://petals.ml/)**
> > - https://petals.ml/
> > - https://research.yandex.com/blog/petals-decentralized-inference-and-finetuning-of-large-language-models
> >
> > **[What is Petals?](https://research.yandex.com/blog/petals-decentralized-inference-and-finetuning-of-large-language-models)**
> >
> > >Run large language models at home, BitTorrent‑style
> >
> > >Run large language models like LLaMA-65B, BLOOM-176B, or BLOOMZ-176B collaboratively — you load a small part of the model, then team up with people serving the other parts to run inference or fine-tuning.
> > >Single-batch inference runs at 5-6 steps/sec for LLaMA-65B and ≈ 1 step/sec for BLOOM — up to 10x faster than offloading, enough for chatbots and other interactive apps. Parallel inference reaches hundreds of tokens/sec.
> > >Beyond classic language model APIs — you can employ any fine-tuning and sampling methods, execute custom paths through the model, or see its hidden states. You get the comforts of an API with the flexibility of PyTorch.
> >
> > - [Colab Link](https://colab.research.google.com/drive/1uCphNY7gfAUkdDrTx21dZZwCOUDCMPw8?usp=sharing)
> > - [GitHub Docs](https://github.com/bigscience-workshop/petals)
> >
> > >**Overview of the Approach**
> >
> > >On a surface level, Petals works as a decentralized pipeline designed for fast inference of neural networks. It splits any given model into several blocks (or layers) that are hosted on different servers. These servers can be spread out across continents, and anybody can connect their own GPU! In turn, users can connect to this network as a client and apply the model to their data.
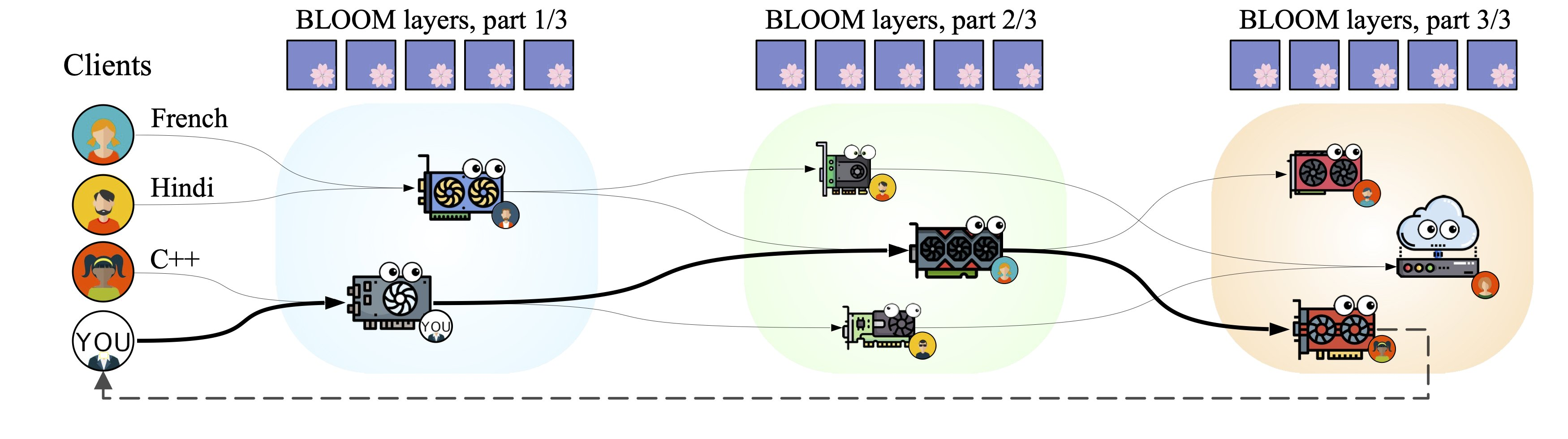
> > When a client sends a request to the network, it is routed through a chain of servers that is built to minimize the total forward pass time. Upon joining the system, each server selects the most optimal set of blocks based on the current bottlenecks within the pipeline. Below, you can see an illustration of Petals for several servers and clients running different inputs for the model.
> >
> > 
> >
> > >**Benchmarks**
> >
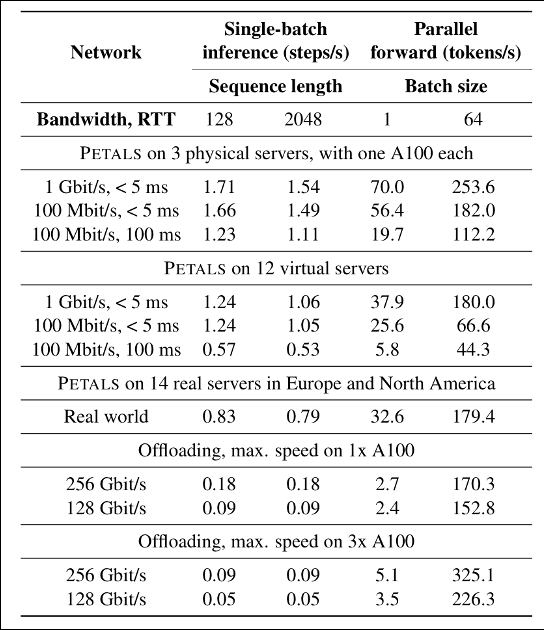
> > >We compare the performance of Petals with offloading, as it is the most popular method for using 100B+ models on local hardware. We test both single-batch inference as an interactive setting and parallel forward pass throughput for a batch processing scenario. Our experiments are run on BLOOM-176B and cover various network conditions, from a few high-speed nodes to real-world Internet links. As you can see from the table below, Petals is predictably slower than offloading in terms of throughput but 3–25x faster in terms of latency when compared in a realistic setup. This means that inference (and sometimes even finetuning) is much faster with Petals, despite the fact that we are using a distributed model instead of a local one.
> >
> > 
> >
> > >**Conclusion**
> >
> > >Our work on Petals continues the line of research towards making the latest advances in deep learning more accessible for everybody. With this work, we demonstrate that it is feasible not only to train large models with volunteer computing, but to run their inference in such a setup as well. The development of Petals is an ongoing effort: it is fully open-source (hosted at https://github.com/bigscience-workshop/petals), and we would be happy to receive any feedback or contributions regarding this project!
> >
> > - [You can read the full article here](https://research.yandex.com/blog/petals-decentralized-inference-and-finetuning-of-large-language-models)
cross-posted from: https://lemmy.world/post/1408916
> 
>
> **[OpenOrca-Preview1-13B Has Been Released](https://huggingface.co/Open-Orca/OpenOrca-Preview1-13B)!**
> - https://huggingface.co/Open-Orca/OpenOrca-Preview1-13B
>
> The Open-Orca team has released OpenOrca-Preview1-13B, a preliminary model that leverages just 6% of their dataset, replicating the Orca paper from [Microsoft Research](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/). The model, fine-tuned on a curated set of 200k GPT-4 entries from the [OpenOrca dataset](https://huggingface.co/datasets/Open-Orca/OpenOrca), demonstrates significant improvements in reasoning capabilities, with a total training cost under $200. This achievement hints at the exciting potential of fine-tuning on the full dataset in future releases.
>
> [OpenOrca-Preview1-13B](https://huggingface.co/Open-Orca/OpenOrca-Preview1-13B) has shown impressive performance on challenging reasoning tasks from BigBench-Hard and AGIEval, as outlined in the Orca paper.
>
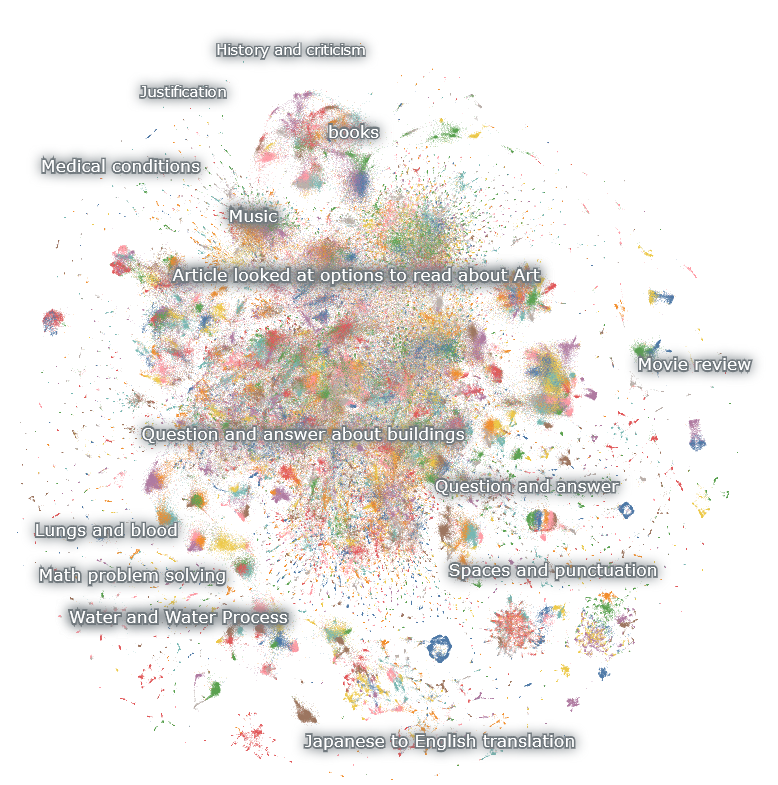
> Even with a small fraction of the dataset, it achieved approximately 60% of the improvement seen in the Orca paper, offering encouraging insights into the scalability of the model. Furthermore, the Open-Orca team has made their Nomic Atlas Dataset Map available for visualizing their dataset, adding another layer of transparency and accessibility to their work.
>
> 
>
> I for one, absolutely love Nomic Atlas. The data visualization is incredible.
>
> **Nomic Atlas**
>
> >Atlas enables you to: Store, update and organize multi-million point datasets of unstructured text, images and embeddings. Visually interact with embeddings of your data from a web browser. Operate over unstructured data and embeddings with topic modeling, semantic duplicate clustering and semantic search.
>
> [You should check out the Atlas for Open Orca. Data is beautiful!](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2)
>
> Here are a few other notable metrics and benchmarks:
>
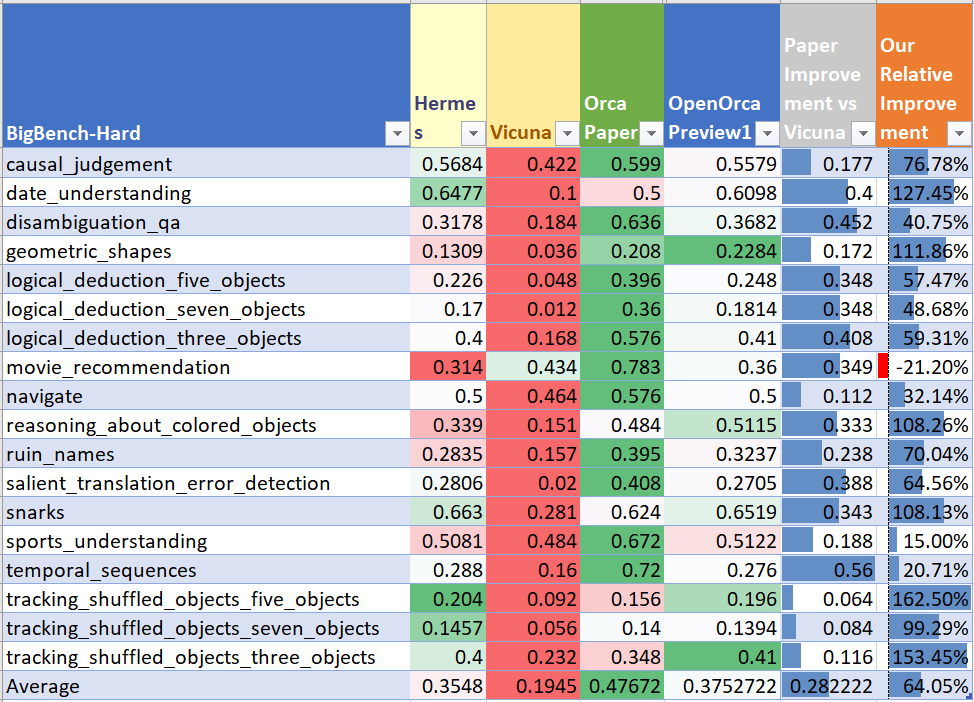
> **BigBench-Hard Performance**
> 
>
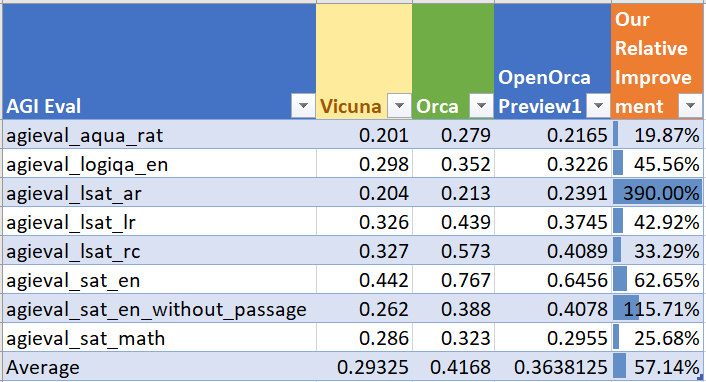
> **AGIEval Performance**
> 
>
> [Looks like they trained this with Axolotl. Love to see it.](https://github.com/OpenAccess-AI-Collective/axolotl)
>
> **Training**
>
> >Built with Axolotl
>
> >We trained with 8x A100-80G GPUs for 15 hours. Commodity cost was < $200.
>
> >We trained for 4 epochs and selected a snapshot at 3 epochs for peak performance.
>
> What an exciting model! Can't wait to see the next wave of releases. It's worth mentioning orca_mini, which is worth checking out if you like this new open-source family of LLMs.
> - https://huggingface.co/psmathur/orca_mini_v2_7b
>
> **The/CUT** (TLDR)
>
> The Open-Orca team has made a groundbreaking open-source breakthrough, creating a cost-effective AI model, OpenOrca-Preview1-13B, that thinks and reasons better using only a tiny portion of their data. This work not only highlights the power of community-driven innovation, but also makes advanced AI accessible and affordable for everyone.
>
> If you found any of this interesting, consider subscribing to [email protected] where I do my best to keep you informed and in the know with the latest breakthroughs in free open-source artificial intelligence.
>
> **Related Posts**
> - [Free Open-Source AI Nexus of Resources](https://lemmy.world/post/814816)
> - [Lemmy Crash Course to Free Open-Source AI](https://lemmy.world/post/76020)
> - [mini_orca_7b](https://lemmy.world/post/1059846)
I run this show solo at the moment, but do my best to keep everyone informed. I have much more content on the horizon. Would love to have you if we have what you’re looking for.
cross-posted from: https://lemmy.world/post/1305651
> **[OpenLM-Research has Released OpenLLaMA: An Open-Source Reproduction of LLaMA](https://github.com/openlm-research/open_llama)**
>
> - https://github.com/openlm-research/open_llama
>
> >**TL;DR**: OpenLM-Research has released a public preview of OpenLLaMA, a permissively licensed open source reproduction of Meta AI’s LLaMA. We are releasing a series of 3B, 7B and 13B models trained on different data mixtures. Our model weights can serve as the drop in replacement of LLaMA in existing implementations.
>
> >In this repo, OpenLM-Research presents a permissively licensed open source reproduction of Meta AI's LLaMA large language model. We are releasing a series of 3B, 7B and 13B models trained on 1T tokens. We provide PyTorch and JAX weights of pre-trained OpenLLaMA models, as well as evaluation results and comparison against the original LLaMA models. The v2 model is better than the old v1 model trained on a different data mixture.
>
> This is pretty incredible news for anyone working with LLaMA or other open-source LLMs. This allows you to utilize the vast ecosystem of developers, weights, and resources that have been created for the LLaMA models, which are very popular in many AI communities right now.
>
> With this, anyone can now hop into LLaMA R&D knowing they have avenues to utilize it within their projects and businesses (commercially).
>
> Big shoutout to the team who made this possible (OpenLM-Research). You should support them by visiting their GitHub and starring the repo.
>
> A handful of varying parameter models have been released by this team, some of which are already circulating and being improved upon.
>
> Yet another very exciting development for FOSS! If I recall correctly, Mark Zuckerberg mentioned in his [recent podcast with Lex Fridman](https://www.youtube.com/watch?v=Ff4fRgnuFgQ) that the next official version of LLaMA from Meta will be open-source as well. I am very curious to see how this model develops this coming year.
>
> If you found any of this interesting, please consider subscribing to [/c/FOSAI](https://lemmy.world/c/fosai) where I do my best to keep you up to date with the most important updates and developments in the space.
>
> Want to get started with FOSAI, but don't know how? Try starting with my [Welcome Message](https://lemmy.world/post/67758) and/or [The FOSAI Nexus](https://lemmy.world/post/814816) & [Lemmy Crash Course to Free Open-Source AI](https://lemmy.world/post/76020).
cross-posted from: https://lemmy.world/post/1102882
> **On 07/05/23, OpenAI Has Announced a New Initiative:**
>
> **[Superalignment](https://openai.com/blog/introducing-superalignment)**
>
> - https://openai.com/blog/introducing-superalignment
>
> Here are a few notes from their article, which you should [read in its entirety](https://openai.com/blog/introducing-superalignment).
>
> >**Introducing Superalignment**
>
> > We need scientific and technical breakthroughs to steer and control AI systems much smarter than us. To solve this problem within four years, we’re starting a new team, co-led by Ilya Sutskever and Jan Leike, and dedicating 20% of the compute we’ve secured to date to this effort. We’re looking for excellent ML researchers and engineers to join us.
>
> >Superintelligence will be the most impactful technology humanity has ever invented, and could help us solve many of the world’s most important problems. But the vast power of superintelligence could also be very dangerous, and could lead to the disempowerment of humanity or even human extinction.
>
> >While superintelligence seems far off now, we believe it could arrive this decade.
>
> >Here we focus on superintelligence rather than AGI to stress a much higher capability level. We have a lot of uncertainty over the speed of development of the technology over the next few years, so we choose to aim for the more difficult target to align a much more capable system.
>
> >Managing these risks will require, among other things, new institutions for governance and solving the problem of superintelligence alignment:
>
> >How do we ensure AI systems much smarter than humans follow human intent?
>
> >Currently, we don't have a solution for steering or controlling a potentially superintelligent AI, and preventing it from going rogue. Our current techniques for aligning AI, such as reinforcement learning from human feedback, rely on humans’ ability to supervise AI. But humans won’t be able to reliably supervise AI systems much smarter than us and so our current alignment techniques will not scale to superintelligence. We need new scientific and technical breakthroughs.
>
> >Other assumptions could also break down in the future, like favorable generalization properties during deployment or our models’ inability to successfully detect and undermine supervision during training.
>
> >**Our approach**
>
> >Our goal is to build a roughly human-level automated alignment researcher. We can then use vast amounts of compute to scale our efforts, and iteratively align superintelligence.
>
> >To align the first automated alignment researcher, we will need to 1) develop a scalable training method, 2) validate the resulting model, and 3) stress test our entire alignment pipeline:
>
> >- 1.) To provide a training signal on tasks that are difficult for humans to evaluate, we can leverage AI systems to assist evaluation of other AI systems (scalable oversight). In addition, we want to understand and control how our models generalize our oversight to tasks we can’t supervise (generalization).
>
> >- 2.) To validate the alignment of our systems, we automate search for problematic behavior (robustness) and problematic internals (automated interpretability).
>
> >- 3.) Finally, we can test our entire pipeline by deliberately training misaligned models, and confirming that our techniques detect the worst kinds of misalignments (adversarial testing).
>
> >We expect our research priorities will evolve substantially as we learn more about the problem and we’ll likely add entirely new research areas. We are planning to share more on our roadmap in the future.
>
> >**The new team**
>
> >We are assembling a team of top machine learning researchers and engineers to work on this problem.
>
> >We are dedicating 20% of the compute we’ve secured to date over the next four years to solving the problem of superintelligence alignment. Our chief basic research bet is our new Superalignment team, but getting this right is critical to achieve our mission and we expect many teams to contribute, from developing new methods to scaling them up to deployment.
>
> [Click Here Read More](https://openai.com/blog/introducing-superalignment).
>
> I believe this is an important notch in the timeline to AGI and Synthetic Superintelligence. I find it very interesting OpenAI is ready to admit the proximity of breakthroughs we are quickly encroaching as a species. I hope we can all benefit from this bright future together.
>
> If you found any of this interesting, please consider subscribing to [/c/FOSAI](https://lemmy.world/c/fosai)!
>
> Thank you for reading!
cross-posted from: https://lemmy.world/post/1034389
> **Greetings Fellow Pioneers of the Fediverse!**
>
> Are you a digital nomad who has recently migrated from another platform? Or perhaps a curious explorer who's caught wind of Lemmy's potential? Have you just begun your journey into the vast and promising landscape of decentralization?
>
> For those still navigating the complexities of our brave new decentralized platform, I highly recommend [watching this video](https://www.youtube.com/watch?v=TrNE2fSCeFo). It does a good job encapsulating some of the immense potential and foundational principles of [The Fediverse](https://www.youtube.com/watch?v=TrNE2fSCeFo).
>
> Once you're up to speed, it's time to delve deeper w/ [FOSAI](https://lemmy.world/post/67758):
>
> Are you experiencing FOMO around emerging technologies? Maybe you're a hobbyist, researcher, or developer passionate about free and open-source projects?
>
> If any of these resonate with you, congratulations! You've landed in the perfect hub for everything related to free and open-source artificial intelligence - a.k.a. FOSAI - a new, sub-movement of FOSS for AI-particular tech stacks and software implementation strategies/platforms.
>
> At FOSAI, my aim is to keep you informed on the latest, most significant advancements in the rapidly evolving landscape of AI/LLM/Diffusion technologies. This endeavor is fueled by my genuine passion and hope for technology, not by clickbait, sensationalism, or social media rage-bait and disinformation campaigns this technology typically gets a bad rap for.
>
> At the end of the day - I don't care how many (or how little) people are following the movement so long as the information I share is valued, true, and used to support a goal that will better your life (and others).
>
> To know more about me and what drives this community, please check out [my welcome message here](https://lemmy.world/post/67758)
>
> Eager to dive into the world of AI today? I recommend visiting my resource-packed [FOSAI Nexus Post](https://lemmy.world/post/814816) or getting acquainted with my [Lemmy Crash Course to Free Open-Source AI](https://lemmy.world/post/76020).
>
> Embracing the philosophy of FOSS, we envision a future where empowerment, creativity, and ethics intertwine seamlessly with technology. Where the human experience is enhanced by innovation, not detracted by it. We believe in a future that lets you experiment with AI in any of its stages easily and accessibly - no matter the cost.
>
> Here, we believe in a future where anyone can work with democratized super intelligent software and platforms that are not controlled by a select few, but by a majority of many. Where you own your data, your technology, what you do with it (and everything between). A future where you are not monitored for every action. Where your data is not being sold to the highest bidder.
>
> A future that is free, a future that is open. A future that is as bright as we make it out to be without compromising the truth of our reality and the direction of our species.
>
> My hope with this community is to foster patience, optimism, and trust in one another. I want to collect and share truths, processes, information, and workflows that educate and enhance our lives, fostering personal growth, development, and change. Real change. Tangible change. Not just the change you have been dreaming for, but the change you deserve.
>
> When posting here, all I ask of you is to [Know Thyself](https://en.wikipedia.org/wiki/Know_thyself), be prepared to engage with [dialogue that is intellectually empathetic](https://en.wikipedia.org/wiki/Socratic_dialogue), and to [share/document processes and knowledge](https://diataxis.fr/) that is empowering to others, no matter their walk of life, experience or technical prowess.
>
> I ask you to know our community. Know the impact of the words you share in earnest and to trust in one another that the empathy in which you seek to support is already there.
>
> If any of this resonates with you, aligns with your thoughts or values, or is interesting in general - please consider subscribing to [/c/FOSAI](https://lemmy.world/c/fosai) [[email protected]](https://lemmy.world/c/fosai)
>
> **Links From This Post**
>
> **Fediverse / FOSAI**
> - The Internet is Healing: https://www.youtube.com/watch?v=TrNE2fSCeFo
> - FOSAI Welcome Message: https://lemmy.world/post/67758
> - FOSAI Nexus Resource Hub: https://lemmy.world/post/814816
> - FOSAI Crash Course: https://lemmy.world/post/76020
>
> **Contributing to Intellectual Empathy & Discussion**
> - The Diataxis Method: https://diataxis.fr
> - Know Thyself: https://en.wikipedia.org/wiki/Know_thyself
> - Socratic Dialogue: https://en.wikipedia.org/wiki/Socratic_dialogue
> - Bonus: https://en.wikipedia.org/wiki/Stoicism
cross-posted from: https://lemmy.world/post/1034389
> **Greetings Fellow Pioneers of the Fediverse!**
>
> Are you a digital nomad who has recently migrated from another platform? Or perhaps a curious explorer who's caught wind of Lemmy's potential? Have you just begun your journey into the vast and promising landscape of decentralization?
>
> For those still navigating the complexities of our brave new decentralized platform, I highly recommend [watching this video](https://www.youtube.com/watch?v=TrNE2fSCeFo). It does a good job encapsulating some of the immense potential and foundational principles of [The Fediverse](https://www.youtube.com/watch?v=TrNE2fSCeFo).
>
> Once you're up to speed, it's time to delve deeper w/ [FOSAI](https://lemmy.world/post/67758):
>
> Are you experiencing FOMO around emerging technologies? Maybe you're a hobbyist, researcher, or developer passionate about free and open-source projects?
>
> If any of these resonate with you, congratulations! You've landed in the perfect hub for everything related to free and open-source artificial intelligence - a.k.a. FOSAI - a new, sub-movement of FOSS for AI-particular tech stacks and software implementation strategies/platforms.
>
> At FOSAI, my aim is to keep you informed on the latest, most significant advancements in the rapidly evolving landscape of AI/LLM/Diffusion technologies. This endeavor is fueled by my genuine passion and hope for technology, not by clickbait, sensationalism, or social media rage-bait and disinformation campaigns this technology typically gets a bad rap for.
>
> At the end of the day - I don't care how many (or how little) people are following the movement so long as the information I share is valued, true, and used to support a goal that will better your life (and others).
>
> To know more about me and what drives this community, please check out [my welcome message here](https://lemmy.world/post/67758)
>
> Eager to dive into the world of AI today? I recommend visiting my resource-packed [FOSAI Nexus Post](https://lemmy.world/post/814816) or getting acquainted with my [Lemmy Crash Course to Free Open-Source AI](https://lemmy.world/post/76020).
>
> Embracing the philosophy of FOSS, we envision a future where empowerment, creativity, and ethics intertwine seamlessly with technology. Where the human experience is enhanced by innovation, not detracted by it. We believe in a future that lets you experiment with AI in any of its stages easily and accessibly - no matter the cost.
>
> Here, we believe in a future where anyone can work with democratized super intelligent software and platforms that are not controlled by a select few, but by a majority of many. Where you own your data, your technology, what you do with it (and everything between). A future where you are not monitored for every action. Where your data is not being sold to the highest bidder.
>
> A future that is free, a future that is open. A future that is as bright as we make it out to be without compromising the truth of our reality and the direction of our species.
>
> My hope with this community is to foster patience, optimism, and trust in one another. I want to collect and share truths, processes, information, and workflows that educate and enhance our lives, fostering personal growth, development, and change. Real change. Tangible change. Not just the change you have been dreaming for, but the change you deserve.
>
> When posting here, all I ask of you is to [Know Thyself](https://en.wikipedia.org/wiki/Know_thyself), be prepared to engage with [dialogue that is intellectually empathetic](https://en.wikipedia.org/wiki/Socratic_dialogue), and to [share/document processes and knowledge](https://diataxis.fr/) that is empowering to others, no matter their walk of life, experience or technical prowess.
>
> I ask you to know our community. Know the impact of the words you share in earnest and to trust in one another that the empathy in which you seek to support is already there.
>
> If any of this resonates with you, aligns with your thoughts or values, or is interesting in general - please consider subscribing to [/c/FOSAI](https://lemmy.world/c/fosai) [[email protected]](https://lemmy.world/c/fosai)
>
> **Links From This Post**
>
> **Fediverse / FOSAI**
> - The Internet is Healing: https://www.youtube.com/watch?v=TrNE2fSCeFo
> - FOSAI Welcome Message: https://lemmy.world/post/67758
> - FOSAI Nexus Resource Hub: https://lemmy.world/post/814816
> - FOSAI Crash Course: https://lemmy.world/post/76020
>
> **Contributing to Intellectual Empathy & Discussion**
> - The Diataxis Method: https://diataxis.fr
> - Know Thyself: https://en.wikipedia.org/wiki/Know_thyself
> - Socratic Dialogue: https://en.wikipedia.org/wiki/Socratic_dialogue
> - Bonus: https://en.wikipedia.org/wiki/Stoicism
# Welcome to the FOSAI Nexus!
**(v0.0.1 - Summer 2023 Edition)**
The goal of this knowledge nexus is to act as a link hub for software, applications, tools, and projects that are all FOSS (free open-source software) designed for AI (FOSAI).
If you haven't already, I recommend bookmarking this page. It is designed to be periodically updated in new versions I release throughout the year. This is due to the rapid rate in which this field is advancing. Breakthroughs are happening weekly. I will try to keep up through the seasons while including links to each sequential nexus post - but it's best to bookmark this since it will be the start of the content series, giving you access to all future nexus posts as I release them.
If you see something here missing that should be added, let me know. I don't have visibility over everything. I would love your help making this nexus better. Like I said in my [welcome message](https://lemmy.world/post/67758), I am no expert in this field, but I teach myself what I can to distill it in ways I find interesting to share with others.
I hope this helps you unblock your workflow or project and empowers you to explore the wonders of emerging artificial intelligence.
Consider subscribing to [/c/FOSAI](https://lemmy.world/c/fosai) if you found any of this interesting. I do my best to make sure you stay in the know with the most important updates to all things free open-source AI.
[Find Us On Lemmy!](https://lemmy.world/c/fosai)
[[email protected]](https://lemmy.world/c/fosai)
---
## Fediverse Resources
**Lemmy**
- [Your Lemmy Crash Course to Free Open-Source AI](https://lemmy.world/post/76020)
- [[email protected]](https://programming.dev/c/auai)
---
## Large Language Model Hub
[Download Models](https://huggingface.co/TheBloke)
### [oobabooga](https://github.com/oobabooga/text-generation-webui)
text-generation-webui - a big community favorite gradio web UI by oobabooga designed for running almost any free open-source and large language models downloaded off of [HuggingFace](https://huggingface.co/TheBloke) which can be (but not limited to) models like LLaMA, llama.cpp, GPT-J, Pythia, OPT, and many others. Its goal is to become the [AUTOMATIC1111/stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) of text generation. It is highly compatible with many formats.
### [Exllama](https://github.com/turboderp/exllama)
A standalone Python/C++/CUDA implementation of Llama for use with 4-bit GPTQ weights, designed to be fast and memory-efficient on modern GPUs.
### [gpt4all](https://github.com/nomic-ai/gpt4all)
Open-source assistant-style large language models that run locally on your CPU. GPT4All is an ecosystem to train and deploy powerful and customized large language models that run locally on consumer-grade processors.
### [TavernAI](https://github.com/TavernAI/TavernAI)
The original branch of software SillyTavern was forked from. This chat interface offers very similar functionalities but has less cross-client compatibilities with other chat and API interfaces (compared to SillyTavern).
### [SillyTavern](https://github.com/SillyTavern/SillyTavern)
Developer-friendly, Multi-API (KoboldAI/CPP, Horde, NovelAI, Ooba, OpenAI+proxies, Poe, WindowAI(Claude!)), Horde SD, System TTS, WorldInfo (lorebooks), customizable UI, auto-translate, and more prompt options than you'd ever want or need. Optional Extras server for more SD/TTS options + ChromaDB/Summarize. Based on a fork of TavernAI 1.2.8
### [Koboldcpp](https://github.com/LostRuins/koboldcpp)
A self-contained distributable from Concedo that exposes llama.cpp function bindings, allowing it to be used via a simulated Kobold API endpoint. What does it mean? You get llama.cpp with a fancy UI, persistent stories, editing tools, save formats, memory, world info, author's note, characters, scenarios, and everything Kobold and Kobold Lite have to offer. In a tiny package around 20 MB in size, excluding model weights.
### [KoboldAI-Client](https://github.com/KoboldAI/KoboldAI-Client)
This is a browser-based front-end for AI-assisted writing with multiple local & remote AI models. It offers the standard array of tools, including Memory, Author's Note, World Info, Save & Load, adjustable AI settings, formatting options, and the ability to import existing AI Dungeon adventures. You can also turn on Adventure mode and play the game like AI Dungeon Unleashed.
### [h2oGPT](https://github.com/h2oai/h2ogpt)
h2oGPT is a large language model (LLM) fine-tuning framework and chatbot UI with document(s) question-answer capabilities. Documents help to ground LLMs against hallucinations by providing them context relevant to the instruction. h2oGPT is fully permissive Apache V2 open-source project for 100% private and secure use of LLMs and document embeddings for document question-answer.
---
## Image Diffusion Hub
[Download Models](https://civitai.com/)
### [StableDiffusion](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
Stable Diffusion is a text-to-image diffusion model capable of generating photo-realistic and stylized images. This is the free alternative to MidJourney. It is rumored that MidJourney originates from a version of Stable Diffusion that is highly modified, tuned, then made proprietary.
### [SDXL (Stable Diffusion XL)](https://clipdrop.co/stable-diffusion)
With [Stable Diffusion XL](https://stability.ai/stablediffusion), you can create descriptive images with shorter prompts and generate words within images. The model is a significant advancement in image generation capabilities, offering enhanced image composition and face generation that results in stunning visuals and realistic aesthetics.
### [ComfyUI](https://github.com/comfyanonymous/ComfyUI)
A powerful and modular stable diffusion GUI and backend. This new and powerful UI will let you design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart-based interface.
### [ControlNet](https://github.com/lllyasviel/ControlNet)
ControlNet is a neural network structure to control diffusion models by adding extra conditions. This is a very popular and powerful extension to add to AUTOMATIC111's stable-diffusion-webui.
### [TemporalKit](https://github.com/CiaraStrawberry/TemporalKit)
An all-in-one solution for adding Temporal Stability to a Stable Diffusion Render via an automatic1111 extension. You must install FFMPEG to path before running this.
### [EbSynth](https://ebsynth.com/)
Bring your paintings to animated life. This software can be used in conjunction with StableDiffusion + ControlNet + TemporalKit workflows.
### [WarpFusion](https://github.com/Sxela/WarpFusion)
A TemporalKit alternative to produce video effects and animation styling.
---
## Training & Education
### LLMs
- [Oobabooga's text-generation-webui](https://github.com/oobabooga/text-generation-webui/blob/main/docs/Training-LoRAs.md)
- [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl)
- [OpenAI Cookbook](https://github.com/openai/openai-cookbook)
- [AemonAlgiz](https://www.youtube.com/@AemonAlgiz)
### Diffusers
- [enigmatic_e](https://www.youtube.com/@enigmatic_e)
- [Albert Bozesan](https://www.youtube.com/@albertbozesan)
- [ControlNet Tutorial](https://www.youtube.com/watch?v=dLM2Gz7GR44)
- [Stable Diffusion + ControlNet + TemporalKit + EbSynth Workflow](https://www.youtube.com/watch?v=rlfhv0gRAF4)
- [Stable Diffusion + Warp Fusion Workflow](https://www.youtube.com/watch?v=m8xaPnaooyg)
---
## Bonus Recommendations
**[AI Business Startup Kit](https://lemmy.world/post/669438)**
**LLM Learning Material from the Developer of SuperHOT** ([kaiokendev](https://kaiokendev.github.io/til)):
>Here are some resources to help with learning LLMs:
>
>[Andrej Karpathy’s GPT from scratch](https://www.youtube.com/watch?v=kCc8FmEb1nY)
>
>[Huggingface’s NLP Course](https://huggingface.co/learn/nlp-course/chapter1/1)
>
>And for training specifically:
>
>[Alpaca LoRA](https://github.com/tloen/alpaca-lora#-alpaca-lora)
>
>[Vicuna](https://github.com/lm-sys/FastChat#fine-tuning)
>
>[Community training guide](https://rentry.org/llm-training)
>
>Of course for papers, I recommend reading anything on arXiv’s CS - Computation & Language that looks interesting to you: [https://arxiv.org/list/cs.CL/recent](https://arxiv.org/list/cs.CL/recent).
---
## Support Developers!
Please consider donating, subscribing to, or buying a coffee for any of the major community developers advancing Free Open-Source Artificial Intelligence.
If you're a developer in this space and would like to have your information added here (or changed), please don't hesitate to [message me](mailto:[email protected])!
[**TheBloke**](https://huggingface.co/TheBloke)
- https://www.patreon.com/TheBlokeAI
[**Oobabooga**](https://github.com/oobabooga/text-generation-webui)
- https://ko-fi.com/oobabooga
[**Eric Hartford**](https://erichartford.com/)
- https://erichartford.com/
[**kaiokendev**](https://kaiokendev.github.io/)
- https://kaiokendev.github.io/
---
**Major FOSAI News & Breakthroughs**
- (June 2023) [MPT-30B: Raising the bar for open-source foundation models](https://www.mosaicml.com/blog/mpt-30b)
- (May 2023) [Google "We Have No Moat, And Neither Does OpenAI"](https://www.semianalysis.com/p/google-we-have-no-moat-and-neither)
- (May 2023) [Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs](https://www.mosaicml.com/blog/mpt-7b)
- (March 2023) [OpenAI Releases Chat-GPT 4](https://openai.com/research/gpt-4)
- (November 2022) [OpenAI Releases Chat-GPT 3](https://openai.com/blog/chatgpt)
- (December 2017) [Attention Is All You Need](https://arxiv.org/abs/1706.03762)
---
Looking for other open-source projects based on these technologies? Consider checking out this [GitHub Repo List](https://github.com/stars/AdynBlaed/lists/fosai?page=1) I made based on stars I have collected throughout the last year or so.
cross-posted from: https://lemmy.world/post/809672
> A very exciting update comes to koboldcpp - an inference software that allows you to run LLMs on your PC locally using your GPU and/or CPU.
>
> Koboldcpp is one of my personal favorites. Shoutout to [LostRuins](https://github.com/LostRuins) for developing this application. Keep the release memes coming!
>
> 
>
> >**[koboldcpp-1.33 Ultimate Edition Release Notes](https://github.com/LostRuins/koboldcpp/releases/tag/v1.33)**
>
> >**A.K.A The "We CUDA had it all edition"**
>
> >The KoboldCpp Ultimate edition is an All-In-One release with previously missing CUDA features added in, with options to support both CL and CUDA properly in a single distributable. You can now select CUDA mode with --usecublas, and optionally low VRAM using --usecublas lowvram. This release also contains support for OpenBLAS, CLBlast (via --useclblast), and CPU-only (No BLAS) inference.
>
> >Back ported CUDA support for all prior versions of GGML file formats for CUDA. CUDA mode now correctly supports every single earlier version of GGML files, (earlier quants from GGML, GGMF, GGJT v1, v2 and v3, with respective feature sets at the time they were released, should load and work correctly.)
>
> >Ported over the memory optimizations I added for OpenCL to CUDA, now CUDA will use less VRAM, and you may be able to use even more layers than upstream in llama.cpp (testing needed).
>
> >Ported over CUDA GPU acceleration via layer offloading for MPT, GPT-2, GPT-J and GPT-NeoX in CUDA.
>
> >Updated Lite, pulled updates from upstream, various minor bugfixes. Also, instruct mode now allows any number of newlines in the start and end tag, configurable by user.
>
> >Added long context support using Scaled RoPE for LLAMA, which you can use by setting --contextsize greater than 2048. It is based off the PR here ggerganov#2019 and should work reasonably well up to over 3k context, possibly higher.
>
> >To use, download and run the koboldcpp.exe, which is a one-file pyinstaller.
> Alternatively, drag and drop a compatible ggml model on top of the .exe, or run it and manually select the model in the popup dialog.
>
>
> >...once loaded, you can connect like this (or use the full koboldai client):
> http://localhost:5001
>
> >For more information, be sure to run the program with the --help flag.
>
> If you found this post interesting, please consider subscribing to the [/c/FOSAI](https://lemmy.world/c/fosai) community at [[email protected]](https://lemmy.world/c/fosai) where I do my best to keep you in the know with the most important updates in free open-source artificial intelligence.
>
> Interested, but not sure where to begin? Try starting with [Your Lemmy Crash Course to Free Open-Source AI](https://lemmy.world/post/76020)
cross-posted from: https://lemmy.world/post/800062
> **Eric Hartford (a.k.a. faldore) has announced [OpenOrca](https://erichartford.com/openorca), an open-source dataset and series of instruct-tuned language models he plans to release alongside Microsoft's new open-source challenger, [Orca](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/).**
>
> You can support Eric and all of the hard work he has done for the open-source community by following his newsletter on his site [here](https://erichartford.com/).
>
> Eric, if you're reading this and would like to share a donation link - I would be more than happy to include it on this post and any future regarding your work. Shoot me a message anytime.
>
> >**Eric Hartford's Announcement**
>
> >*Today I'm announcing OpenOrca.*
>
> >https://erichartford.com/openorca
>
> >https://twitter.com/erhartford/status/1674214496301383680
>
> >The dataset is completed. ~1mil of GPT4 augmented flanv2 instructions and ~3.5mil of GPT3.5 augmented flanv2 instructions.
>
> >We are currently training on LLaMA-13b. We expect completion in about 2 weeks.
>
> >When training is complete, we will release the dataset and the model at the same time.
>
> >We are seeking GPU compute sponsors for various targets, please consult the blog post and reach out if interested.
>
> >Thank you to our sponsors!
>
> >https://chirper.ai
>
> >https://preemo.io
>
> >https://latitude.sh
>
> A few more highlights from the full article, which you should read [here](https://erichartford.com/openorca) when you have a chance.
>
> >We expect to release OpenOrca-LLaMA-13b in mid-July 2023. At that time we will publish our evaluation findings and the dataset.
>
> >We are currently seeking GPU compute sponsors for training OpenOrca on the following platforms:
>
> Falcon 7b, 40b
>
> LLaMA 7b, 13b, 33b, 65b
>
> MPT-7b, 30b
>
> Any other targets that get a sponsor. (RWKV, OpenLLaMA)
>
> >**Dataset consists of:**
>
> - ~1 million of FLANv2 augmented with GPT-4 completions
>
> - ~3.5 million of FLANv2 augmented with GPT-3.5 completions
>
> If you found this post interesting, please consider subscribing to the [/c/FOSAI](https://lemmy.world/c/fosai) community at [[email protected]](https://lemmy.world/c/fosai) where I do my best to keep you in the know with the most important updates in free open-source artificial intelligence.
cross-posted from: https://lemmy.world/post/708817
> [**Visit TheBloke's HuggingFace**](https://huggingface.co/TheBloke) page to see all of the new models in their SuperHOT glory.
>
> SuperHOT models are LLMs who's LoRAs have been adapted to support a context length of 8,000 tokens!
>
> For reference, this is x4 times the default amount of many LLMs (i.e. 2048 tokens). Even some of the newer ones can only reach a context length of 4096 tokens, half the amount of these SuperHOT models!
>
> Here are a few that were released if you couldn't view his HuggingFace:
>
> **[New GPTQ Models from TheBloke](https://huggingface.co/TheBloke)**
> - airoboros (13B)
> - CAMEL (13B)
> - Chronos (13B)
> - Guanaco (13B & 33B)
> - Manticore (13B)
> - Minotaur (13B)
> - Nous Hermes (13B)
> - Pygmalion (13B)
> - Samantha (13B & 33B)
> - Snoozy (13B)
> - Tulu (13B & 33B)
> - Vicuna (13B & 33B)
> - WizardLM (13B)
>
> We owe a tremendous thank you to TheBloke, who has enabled many of us in the community to interact with versions of Manticore, Nous Hermes, WizardLM and others running the remarkable 8k context length from SuperHOT.
>
> Many of these are 13B models, which should be compatible with consumer grade GPUs. Try using Exllama or Oobabooga for testing out these new formats.
>
> Shoutout to Kaikendev for the creation of SuperHOT. [You can learn more about their work here.](https://kaiokendev.github.io/) or in [Meta's new research paper covering this method](https://arxiv.org/abs/2306.15595).
>
> If you enjoyed reading this, please consider subscribing to [/c/FOSAI](https://lemmy.world/c/fosai) where I do my best to keep you in the know with the latest and greatest advancements regarding free open-source artificial intelligence.
cross-posted from: https://lemmy.world/post/708817
> [**Visit TheBloke's HuggingFace**](https://huggingface.co/TheBloke) page to see all of the new models in their SuperHOT glory.
>
> SuperHOT models are LLMs who's LoRAs have been adapted to support a context length of 8,000 tokens!
>
> For reference, this is x4 times the default amount of many LLMs (i.e. 2048 tokens). Even some of the newer ones can only reach a context length of 4096 tokens, half the amount of these SuperHOT models!
>
> Here are a few that were released if you couldn't view his HuggingFace:
>
> **[New GPTQ Models from TheBloke](https://huggingface.co/TheBloke)**
> - airoboros (13B)
> - CAMEL (13B)
> - Chronos (13B)
> - Guanaco (13B & 33B)
> - Manticore (13B)
> - Minotaur (13B)
> - Nous Hermes (13B)
> - Pygmalion (13B)
> - Samantha (13B & 33B)
> - Snoozy (13B)
> - Tulu (13B & 33B)
> - Vicuna (13B & 33B)
> - WizardLM (13B)
>
> We owe a tremendous thank you to TheBloke, who has enabled many of us in the community to interact with versions of Manticore, Nous Hermes, WizardLM and others running the remarkable 8k context length from SuperHOT.
>
> Many of these are 13B models, which should be compatible with consumer grade GPUs. Try using Exllama or Oobabooga for testing out these new formats.
>
> Shoutout to Kaikendev for the creation of SuperHOT. [You can learn more about their work here.](https://kaiokendev.github.io/)
>
> If you enjoyed reading this, please consider subscribing to [/c/FOSAI](https://lemmy.world/c/fosai) where I do my best to keep you in the know with the latest and greatest advancements regarding free open-source artificial intelligence.
cross-posted from: https://lemmy.world/post/699214
> Hello everyone!
>
> I'd like to share with you another new resource: **[NLP Cloud](https://nlpcloud.com/)** - a provider and platform aimed to help you streamline AI/LLM deployments for your business or project.
>
> If you're considering a startup in AI, this is a valuable read and resource. Support these developers by visiting their site and checking out the platform for yourself.
>
> >**NLP Cloud (Natural Language Processing Cloud)**
>
> >GPT-3, GPT-4, ChatGPT, GPT-J, and generative models in general, are very powerful AI models. We're showing you here how to effectively use these models thanks to few-shot learning, also known as prompt engineering. Few-shot learning is like training/fine-tuning an AI model, by simply giving a couple of examples in your prompt.
>
> >**GPT-3, GPT-4, And ChatGPT**
>
> >GPT-3, GPT-4, and ChatGPT, released by OpenAI, are the most powerful AI model ever released for text understanding and text generation.
>
> >GPT-3 was trained on 175 billion parameters, which makes it extremely versatile and able to understanding pretty much anything! We do not know the number of parameters in GPT-4 but results are even more impressive.
>
> >You can do all sorts of things with these generative models like chatbots, content creation, entity extraction, classification, summarization, and much more. But it takes some practice and using them correctly might require a bit of work.
>
> >**GPT-J, GPT-NeoX, And Dolphin**
>
> >GPT-NeoX and GPT-J are both open-source Natural Language Processing models, created by, a collective of researchers working to open source AI (see EleutherAI's website).
>
> >GPT-J has 6 billion parameters and GPT-NeoX has 20 billion parameters, which makes them the most advanced open-source Natural Language Processing models as of this writing. They are direct alternatives to OpenAI's proprietary GPT-3 Curie.
>
> >These models are very versatile. They can be used for almost any Natural Language Processing use case: text generation, sentiment analysis, classification, machine translation,... and much more (see below). However using them effectively sometimes takes practice. Their response time (latency) might also be longer than more standard Natural Language Processing models.
>
> >GPT-J and GPT-NeoX are both available on the NLP Cloud API. On NLP Cloud you can also use Dolphin, an in-house advanced generative model that competes with ChatGPT, GPT-3, and even GPT-4. Below, we're showing you examples obtained using the GPT-J endpoint of NLP Cloud on GPU, with the Python client. If you want to copy paste the examples, please don't forget to add your own API token. In order to install the Python client, first run the following: pip install nlpcloud.
>
> >**Few-Shot Learning**
>
> >Few-shot learning is about helping a machine learning model make predictions thanks to only a couple of examples. No need to train a new model here: models à la GPT-3 and GPT-4 are so big that they can easily adapt to many contexts without being re-trained.
>
> >Giving only a few examples to the model does help it dramatically increase its accuracy.
>
> >In Natural Language Processing, the idea is to pass these examples along with your text input. See the examples below!
>
> >Also note that, if few-shot learning is not enough, you can also fine-tune GPT-3 on OpenAI's website and GPT-J and Dolphin on NLP Cloud so the models are perfectly tailored to your use case.
>
> >You can easily test few-shot learning on the NLP Cloud Playground, in the text generation section. Click here to try text generation on the Playground. Then simply use one of the examples showed below in this article and see for yourself.
>
> >If you use a model that understands natural human instructions like ChatGPT or ChatDolphin, you might not always have to use few-shot learning, but it is alway interesting to apply few-shot learning when possible in order to get the most advanced results. If you do not want to use few-shot learning, read our dedicated guide about how to use ChatGPT and ChatDolphin with simple instructions: see the article here.
>
> In my opinion, I think this is a big highlight of this service:
>
> >**Data Privacy And Security**
>
> >NLP Cloud is HIPAA / GDPR / CCPA compliant, and working on the SOC 2 certification. We cannot see your data, we do not store your data, and we do not use your data to train our own AI models.
>
> [You can read the full page and article here](https://nlpcloud.com/effectively-using-gpt-j-gpt-neo-gpt-3-alternatives-few-shot-learning.html?utm_source=reddit&utm_campaign=e859w625-3816-11ed-a261-0242ac140007). If you're still interested, consider checking out [this other amazing resource detailing how to utilize chat-gpt alternatives](https://nlpcloud.com/effectively-using-chatdolphin-the-chatgpt-alternative-with-simple-instructions.html?utm_source=reddit&utm_campaign=e859w625-3816-11ed-a261-0242ac140007).
cross-posted from: https://lemmy.world/post/440237
> The latest update of Koboldcpp v1.32 brings significant performance boosts to AI computations at home, enabling faster generation speeds and improved memory management for several AI models like MPT, GPT-2, GPT-J and GPT-NeoX, plus upgraded K-Quant matmul kernels for OpenCL.
>
> By leveraging GPU power via OpenCL and implementing optimized programming techniques, it allows hobbyist and enthusiast users to run these advanced models more efficiently on home hardware.
>
> **[LostRuin's Koboldcpp v1.32 GitHub Patch Notes](https://github.com/LostRuins/koboldcpp/releases/tag/v1.32)**
>
> 
> >- Ported the optimized K-Quant CUDA kernels to OpenCL ! This speeds up K-Quants generation speed by about 15% with CL (Special thanks: @0cc4m)
>
> >- Implemented basic GPU offloading for MPT, GPT-2, GPT-J and GPT-NeoX via OpenCL! It still keeps a copy of the weights in RAM, but generation speed for these models should now be much faster! (50% speedup for GPT-J, and even WizardCoder is now 30% faster for me.)
>
> >- Implemented scratch buffers for the latest versions of all non-llama architectures except RWKV (MPT, GPT-2, NeoX, GPT-J), BLAS memory usage should be much lower on average, and larger BLAS batch sizes will be usable on these models.
>
> >- Merged GPT-Tokenizer improvements for non-llama models. Support Starcoder special added tokens. Coherence for non-llama models should be improved.
>
> >- Updated Lite, pulled updates from upstream, various minor bugfixes.
>
> >To use, download and run the koboldcpp.exe, which is a one-file pyinstaller.
> >Alternatively, drag and drop a compatible ggml model on top of the .exe, or run it and manually select the model in the popup dialog.
>
> >Once loaded, you can connect like this (or use the full koboldai client):
>
> >http://localhost:5001
>
> >For more information, be sure to run the program with the --help flag.
>
> Want to run AI models at home? Checkout [Koboldcpp ](https://github.com/LostRuins/koboldcpp)on Github, an inference engine made by LostRuins, or any of the [other many options you can download at home for free.](https://lemmy.world/post/76020)
cross-posted from: https://lemmy.world/post/228673
> I would like to share with everyone an incredible resource put together by the LMSYS Org.
>
> In essence, it is a new Elo rating leaderboard for large language models based on anonymous voting data collected in the wild. I will be sharing major updates to this leaderboard regularly.
>
> If you have no idea what is going on in AI and simply want to be in the know in regards to which models in the open-source communities are the best - this is the thread for you.
>
> Consider visiting and subscribing to [/c/FOSAI](https://lemmy.world/c/fosai) if you want to keep up with the latest and greatest advancements in free, open-source artificial intelligence.
>
> You should also bookmark or save this leaked article from one of Google's employees. It does a great job illustrating how big tech companies are scrambling to contain free, open-source AI.
>
> [Google "We Have No Moat, And Neither Does OpenAI"](https://www.semianalysis.com/p/google-we-have-no-moat-and-neither)
>
> It is a fascinating insight into some of the minds that pioneered this technology in the first place. We can do a deeper conversational post on this article later on, but watching how it ages over these coming months will be interesting to say the least.
>
> 
>
> I did not make this leaderboard, so if you want more insights into the rankings please visit the [LMSYS ](https://lmsys.org/blog/2023-05-25-leaderboard/)site to show your support and dive deeper into the models.
>
> For fun, I asked GPT-4 to convert the table into eSport inspired ladder rankings. These were the results. Hopefully this helps give you a better frame of reference for this field of emerging tech.
>
> - **Challenger #1** - GPT-4 by OpenAI (Elo Rating: 1225) - This is a proprietary model.
> - **Challenger #2** - Claude-v1 by Anthropic (Elo Rating: 1195) - This is also a proprietary model.
> - **Challenger #3** - Claude-instant-v1 (Elo Rating: 1153) - This model is lighter, less expensive, and much faster version of Claude. It's a proprietary model as well.
> - **Master** - GPT-3.5-turbo by OpenAI (Elo Rating: 1143) - Another proprietary model from OpenAI.
> - **Diamond I** - Vicuna-13B (Elo Rating: 1054) - This is a chat assistant fine-tuned from LLaMA on user-shared conversations by LMSYS. The weights are available for non-commercial use.
> - **Diamond II** - PaLM 2 (Elo Rating: 1042) - This is a chat model tuned for chat and powers Bard. It's a proprietary model.
> - **Diamond III** - Vicuna-7B (Elo Rating: 1007) - Similar to Vicuna-13B, this model has also been fine-tuned from LLaMA on user-shared conversations by LMSYS. The weights are available for non-commercial use.
> - **Platinum I** - Koala-13B (Elo Rating: 980) - A dialogue model for academic research by BAIR. The weights are available for non-commercial use.
> - **Platinum II** - mpt-7b-chat (Elo Rating: 952) - This is a chatbot fine-tuned from MPT-7B by MosaicML. It is released under CC-By-NC-SA-4.0 license.
> - **Platinum III** - FastChat-T5-3B (Elo Rating: 941) - This chat assistant was fine-tuned from FLAN-T5 by LMSYS. It's available under Apache 2.0 license.
> - **Gold I** - Alpaca-13B (Elo Rating: 937) - This model is fine-tuned from LLaMA on instruction-following demonstrations by Stanford. The weights are available for non-commercial use.
> - **Gold II** - RWKV-4-Raven-14B (Elo Rating: 928) - An RNN with transformer-level LLM performance. It's available under Apache 2.0 license.
> - **Gold III** - Oasst-Pythia-12B (Elo Rating: 921) - An Open Assistant for everyone by LAION. It's also available under Apache 2.0 license.
> - **Silver I** - ChatGLM-6B (Elo Rating: 921) - An open bilingual dialogue language model by Tsinghua University. The weights are available for non-commercial use.
> - **Silver II** - StableLM-Tuned-Alpha-7B (Elo Rating: 882) - Stability AI language models. These models are released under CC-BY-NC-SA-4.0 license.
> - **Silver III** - Dolly-V2-12B (Elo Rating: 866) - An instruction-tuned open large language model by Databricks. It is
>
> I think we all recognize #1. But notice how fast we are in catching up. In case you forgot, GPT-4 was released by OpenAI on March 14, 2023. Three months later we have multiple competing models with many commercially available ones not far behind.
>
> This leaderboard is a testament to the power of open-source. Perhaps there is a moat, perhaps there isn't. I don't know the answer to this, but I am very hopeful we'll see some incredible breakthroughs in our lifetimes. Perhaps even in the near future if we continue advancing at this rapid pace.
>
> It's also important to consider [NVIDIA's Grace Hopper AI Superchip](https://www.nvidia.com/en-us/data-center/grace-hopper-superchip/) was announced not too long ago. [With AMDs surge towards AI](https://lemmy.world/post/135600), we're in for a boom in the coming years.
>
> What does that mean for us? For you? For technology as a whole?
>
> I know this is a lot to keep up with, so if you're overwhelmed, consider subscribing. All will be explained in due time! This next year is going to be very interesting. I appreciate you taking a break from Reddit and sharing this journey with us here.
>
> We have many more exciting news around the corner. We'll do our best to break it down ELI5 style and in-depth for those who want a deep dive into the technology and how it all works.
 English
English


I used to feel the same way until I found some very interesting performance results from 3B and 7B parameter models.
Granted, it wasn’t anything I’d deploy to production - but using the smaller models to prototype quick ideas is great before having to rent a gpu and spend time working with the bigger models.
Give a few models a try! You might be pleasantly surprised. There’s plenty to choose from too. You will get wildly different results depending on your use case and prompting approach.
Let us know if you end up finding one you like! I think it is only a matter of time before we’re running 40B+ parameters at home (casually).